nplotを使用したAmazon Book reviewの可視化
今回は自然言語処理のための分析・可視化モジュールであるnlplotでどんなことが出来るのか実際に使ってみました、
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
今回使用したデータ:https://www.kaggle.com/datasets/mohamedbakhet/amazon-books-reviews
・Books_rating
212,404冊のユニークな本に関するフィードバックが含まれている。
期間は1996/05から2014/07
・books_data
212,404冊のユニークな本に関する詳細情報
○nplotとは何か?
nplotとは自然言語処理のための分析・可視化モジュールになります。通常、テキストデータは分ち書きを行った後、可視化したい内容によりベクトル化の処理が異なってきます。そのため、複数の可視化を行うため工数がかかります。nlplotでは下記の可視化が簡単に行える機能があります。
・bar chart
・tree map
・histogram
・wordcloud
・co-occurrence network
・sunburst chart
※日本語テキストの場合はトークナイザしている必要があります
○では、早速nlplotを使用してみましょう。
今回使用するデータは下記の2つになります。

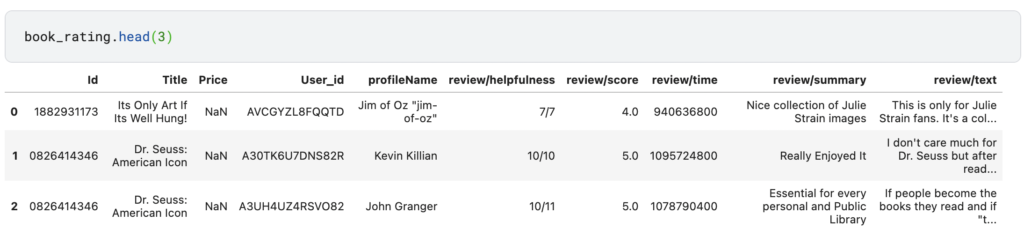
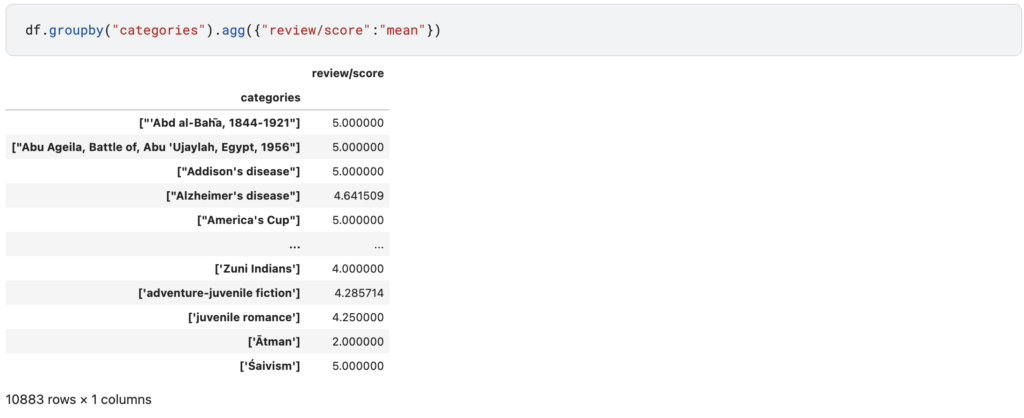
日本みたいにサスペンス、恋愛などの単純なカテゴリーを想像していましたが10,883種類あるみたいです。今回はnlplotを使用してみることに主眼を置きたいためカテゴリーは一旦飛ばす事にします。
nlplotを行うにあたり準備をします。
必要な前処理は単語分割のみ(英語の場合)のため、split(” “)でスペースを軸に区切るだけで実装できます。日本語の場合はトークナイザを行う必要があるため注意が必要です。
今回はデータ数が多かったため、レビューが1のものと4のものに絞って比較を行っていきます。
参考にしたサイトは下記の二つになります。
・https://boxcode.jp/nlplot%E3%81%8C%E5%87%84%E3%81%84%EF%BC%81%E8%87%AA%E7%84%B6%E8%A8%80%E8%AA%9E%E3%82%92%E5%8F%AF%E8%A6%96%E5%8C%96%E3%83%BB%E5%88%86%E6%9E%90%E3%81%A7%E3%81%8D%E3%82%8Bpython%E3%83%A9%E3%82%A4
・https://www.takapy.work/entry/2020/05/17/192947
試しにレビュー評価が4だったレビューの出現単語数の多い順に上位30位を可視化してみます。
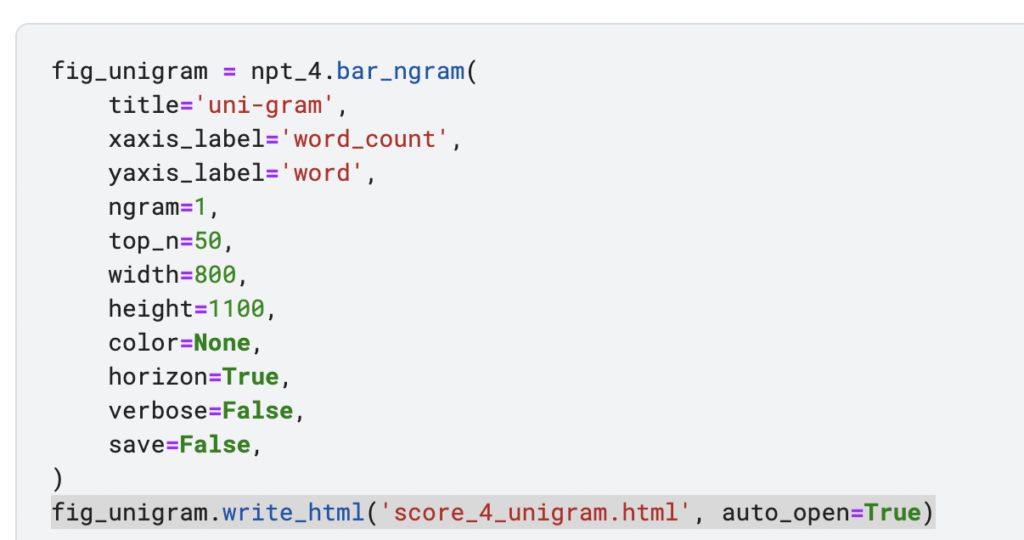
これらの意味の無い単語はあらかじめ分割した際に削除するかnplotのstopwordで頻出上位単語上位○位まで表示しないことも可能です。
棒グラフではなくツリーマップで表示することもできます。

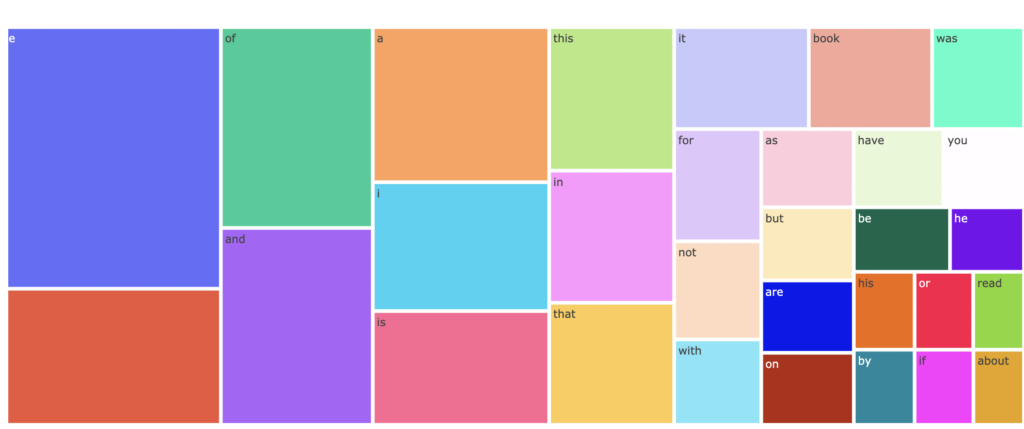
よく見る可視化も簡単に実装できます。

レビュー1

100まで出現単語数を増やすと本の内容に触れていそうなものもちらほら出てきます。
characterなどレビュー1とレビュー4の双方に出てきているものは同一単語でも良い評価と悪い評価と考えることが出来るためレビュー1の方ではキャラクターが悪かったか?といった簡単な仮説は立てることが出来そうです。
○まとめ
今回はnplotを使用してテキストの可視化を行ってみました。ベクトル化→可視化など通常の方法で行おうとすると工数が多く大変ですがnplotを使用すれば簡単に可視化が可能なため全体像を把握して仮説を立てる際に非常に便利に感じました。また、改めてデータのクレンジングの重要性を今回感じました。レビュー内容に直接影響のないものに関してはあらかじめ処理しておかないと本当に見たい結果が出てこないことを身をもって体感しました。
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
コメントを残す