dbt(data build tool)を使ってみた
今回はdbtというELTのT(transformation)部分を担う変換ワークフローツールについて、ドキュメントのチュートリアルに沿って実行してみたので備忘録的な記事になります。
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
○dbtとは
冒頭でも記載しましたがdbtとはELTのT部分を担う変換ワークフローツールになります。dbt内でデータの抽出などは行えず、BigqueryやRedshiftなどに格納してるデータを加工してデータウェアハウスに書き戻す変換に特化しています。
○dbtの特徴は?
dbtの特徴としては下記の4点が挙げられます
・SELECT文やpythonのDataFrameのみでデータマートを作成することが可能
・データの品質テストを実行可能
・データの依存関係を説明するドキュメントや有効グラフを自動作成
・C I/CDなどソフトウェア開発手法が活用可能
○モデルの開発
今回はチュートリアルに沿ってBigquery内にある`dbt-tutorial`.jaffle_shop.orders(注文履歴)と`dbt-tutorial`.jaffle_shop.customers(会員情報)を結合してcustomersというデータマートを作成したいと思います。
実施した手順としては下記になります。
・ブランチの作成
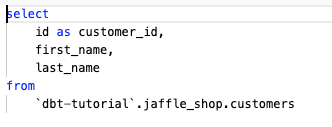
・会員情報・注文履歴のテーブルから必要な情報を抽出するstg_customers.sql、stg_orderssql.sqlファイルを作成します(図1)
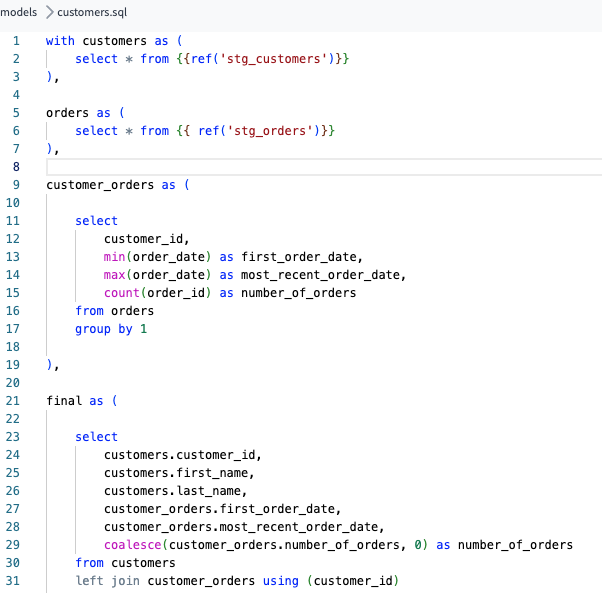
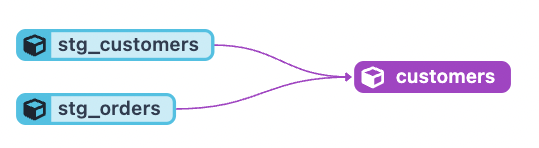
・customersテーブルを作成するためのcustomers.sqlを作成します。このとき、元となるテーブルは上記のstg_customers.sql、stg_orderssql.sqlのクエリで作成したものを利用したいためFROM ({ref(‘stg_customers’})とrefを使用します。refでは実際のテーブル名ではなくモデルを指定することで依存関係の解釈がされます(図2,3)
・dbt runで実行することで作成したモデルを実行します。
○testの実行
schema.ymlというファイルにtestする項目を記述することで品質チェックを行うことが出来ます。
チェックできる項目は下記の4つになります。
・unique : 意図しない重複が発生していないか
・not_null : 意図しないnullがないか確認
・accepted_values : 意図しないデータが格納されていないか
・relationships : 整合性が取れているか確認
dbt testを実行することでschema.ymlを反復処理し、テストごとにクエリを作成し失敗したレコードの数を返します。この数値が0の場合、テストは成功と判断できます。

○ドキュメントの作成
dbt docs generateを実行すると依存関係を記述したjsonファイルを生成します。
○まとめ
dbtを利用することでデータの依存関係を把握しやすくなるため、複数のテーブルからJOINしているSQLの管理がしやすくなると感じました。また、データの品質に問題ないかチェックを行ってくれるため、最低限の品質管理が行えることも魅力的でした。次週からはdbtを利用して、自身のBigqueryデータを用いてパイプラインを設計し、最終的にはダッシュボードを作っていきたいと思います!
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。
(前回から大分更新が途絶えていましたが…)
データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
○参考
dbtドキュメント:https://docs.getdbt.com/
dbtで始めるデータパイプライン構築〜入門から実践〜:https://zenn.dev/dbt_tokyo/books/537de43829f3a0
1件のコメント