SHAPによる特徴量の可視化
今回はsklearn.datasetの一つであるbostonのデータを用いて、shapによる特徴量の可視化を行いたいと思います。今回はshapを使ってみる、解釈の仕方を学ぶことに重点を置いて行いました。
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
今回使用したコードは下記のURLから確認できます。
github:https://github.com/ryosuke-yakura/shap
○Shapについて(ざっくりと)
Shapについて調べるにあたり、下記のURLのサイトを参考にさせていただきました。DataRobot:https://www.datarobot.com/jp/blog/explain-machine-learning-models-using-shap/
Shapはゲーム理論で用いられるシャープレイ値を機械学習に応用したライブラリになります。
各特徴量にはshap値という予測への寄与度を計算した数値が使用され、「特定の特徴量の値が変わったときにどの程度予測値に影響するか」を簡単に調べることができます。
計算量が多いため、大規模のデータを元に使用すると実行までに時間がかかるためセグメント毎や一定数で区切って使用すると良いと思います。
○Shap使用前の準備
まずはShapを使用するために機械学習を行います。今回は冒頭お話したようにsklearnのボストン住宅価格データセットを使用します。
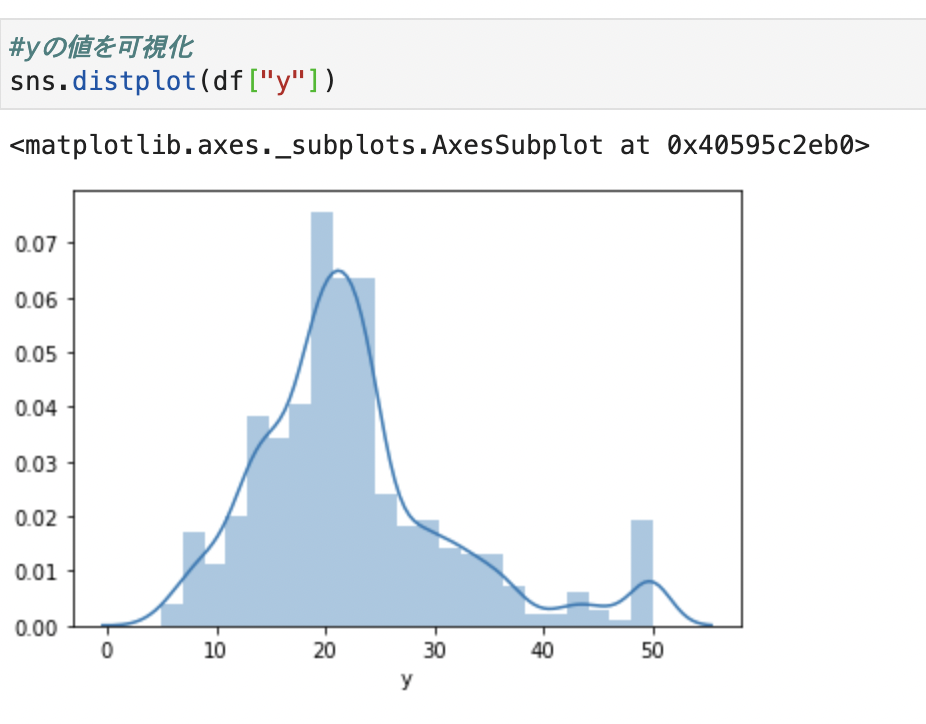
20近傍が山の頂上となっており、大まかに正規分布の形をしています。
では、特に前処理等は行わずに早速学習させてみましょう。
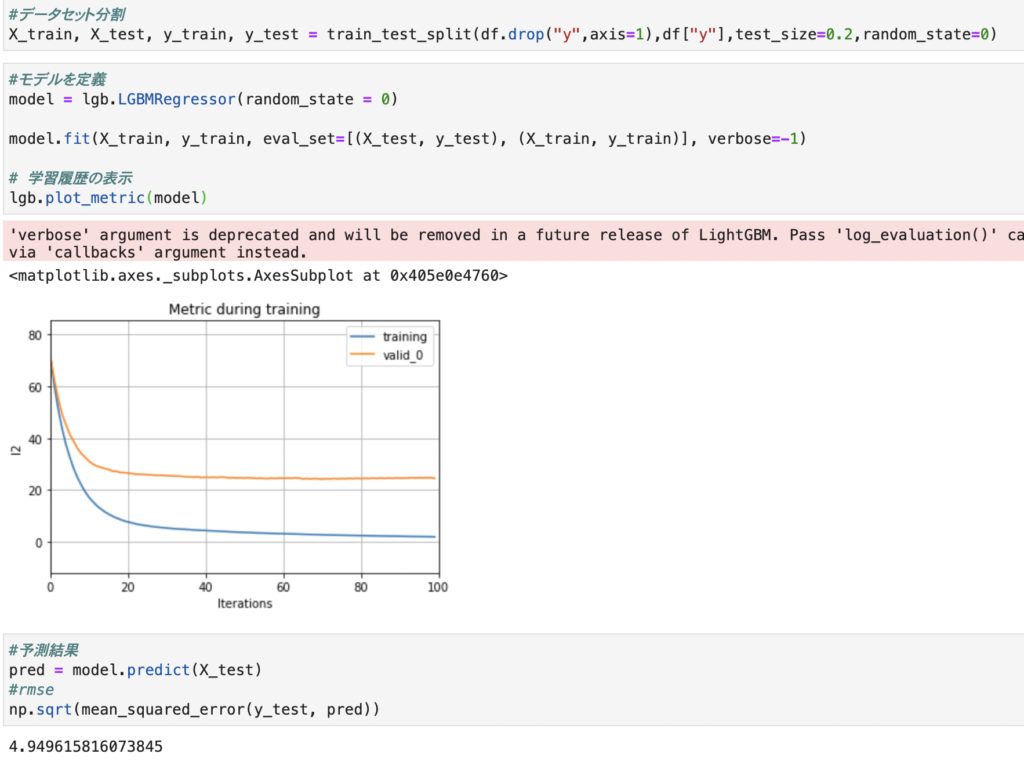
今回のデータは500行程でありデータ数が少ないため、実際にはlightgbmなどの機械学習を使うよりも決定木など単純なモデルの方が良いと思います。
今回はshapでの可視化が目的ということでこのまま進めていきます。
○Shapを使用
では、モデルも作れたところでShapを使用していきましょう。
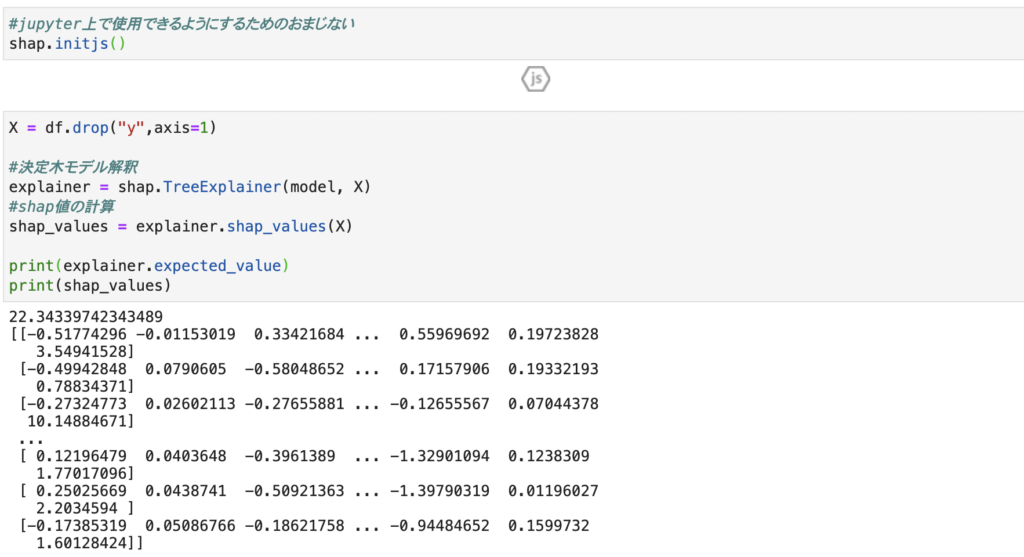
最初のコードはjupyter notebookで使用できるようにするためのおまじないになります。
2番目のセルでshap値を計算しています。
ここまで出来れば後は知りたい内容に合致したコードをドキュメントから引用して可視化していきます。
URL:https://shap.readthedocs.io/en/latest/example_notebooks/tabular_examples/tree_based_models/Census%20income%20classification%20with%20LightGBM.html?highlight=treeexplainer
まずは特徴量の影響度を見ていきます。
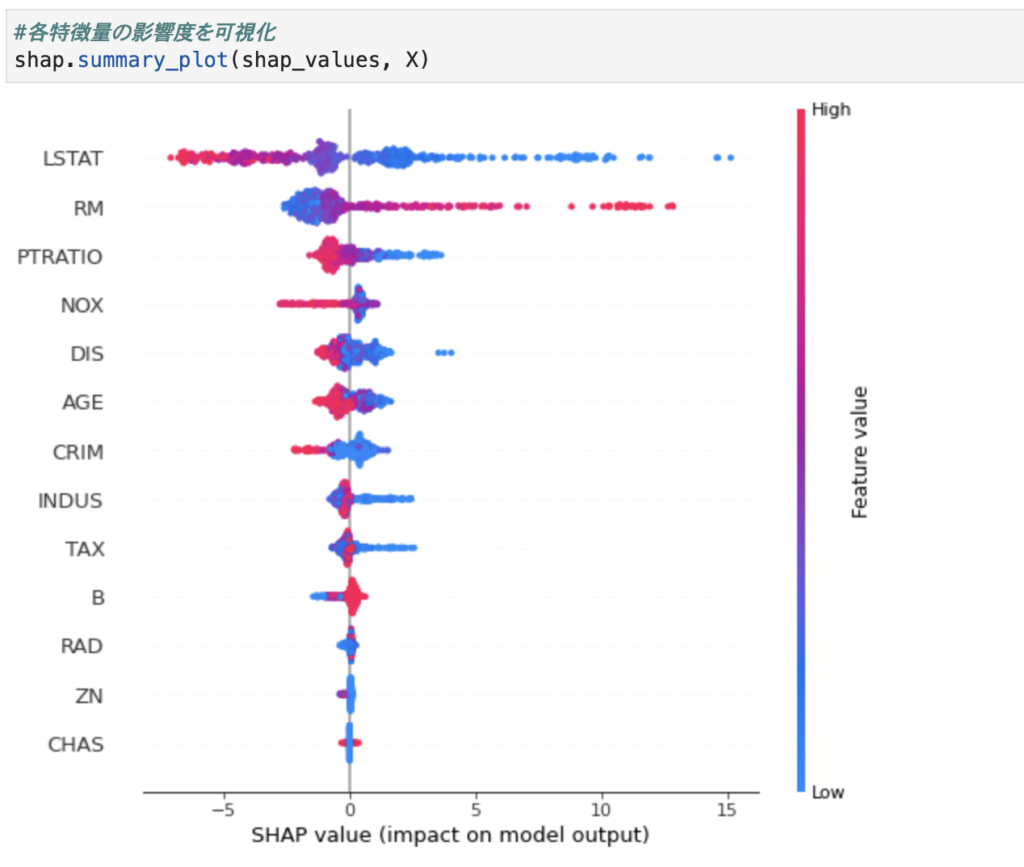
これを見るとLSTATが一番影響度が高く、値が大きいほど予測結果は低く予測しています。
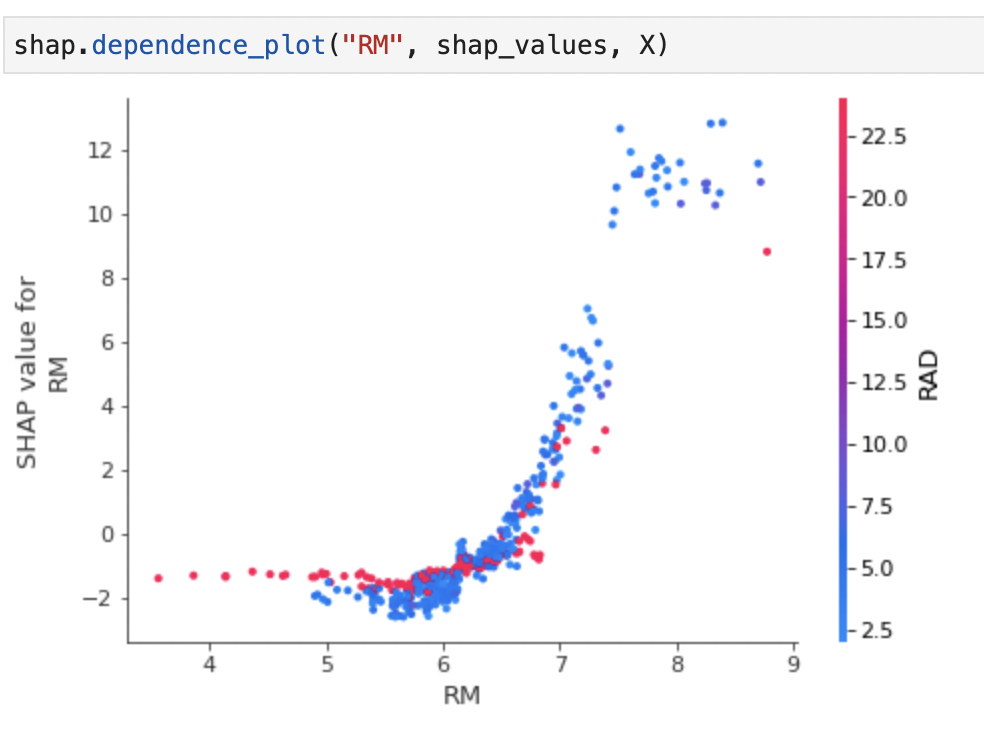
RM(1住戸辺りの平均部屋数)は大きいほど予測結果も高くなっていると考えられます。
試しに一つのデータを除いてみましょう。

BやNOX、LSTATが予測結果を上げており、AGEやINDUSなどが下げていることがわかります。
あくまで1つのデータを見ただけのため、全体の傾向とは言えないので注意が必要です。
そこで今度は全体のデータで見ていきましょう。
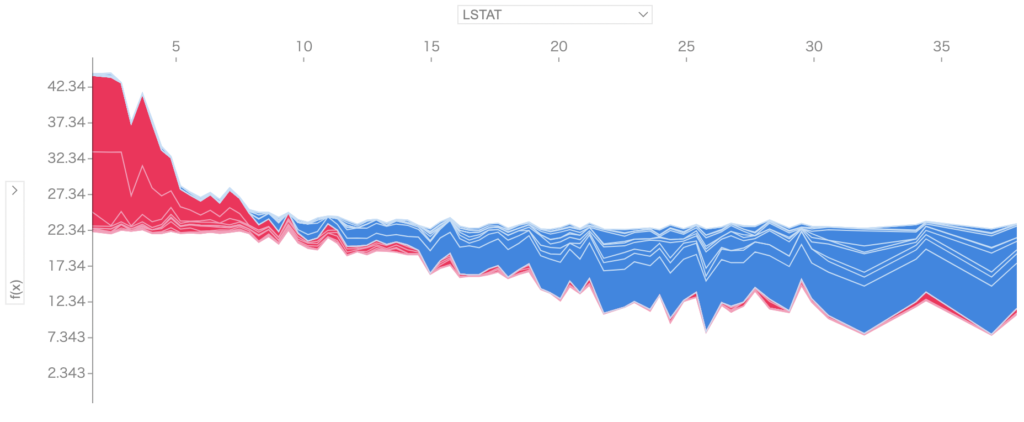
LSTATは値が高くなるほど予測結果が低くなることがわかります。
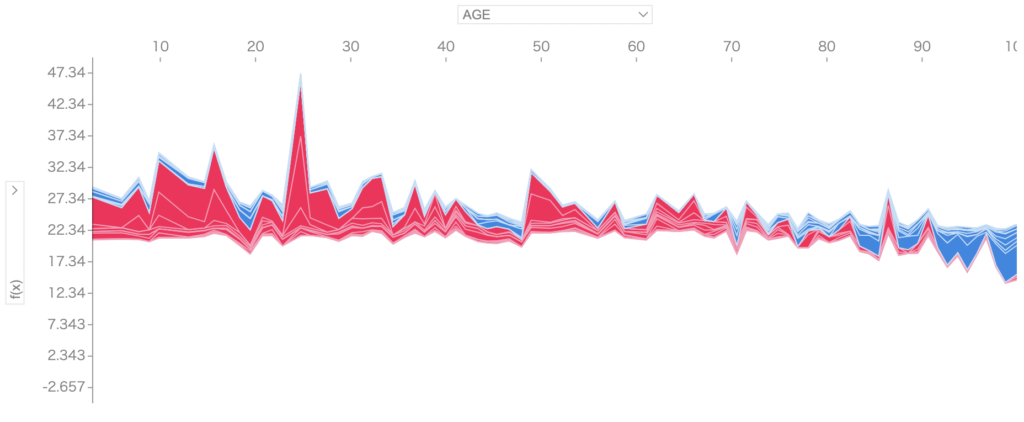
したの図のAGEもLSTATほどではないが高くなるほど予測結果が低くなっています。
次に予測結果に辿り着くまでの動きを見ていきます。
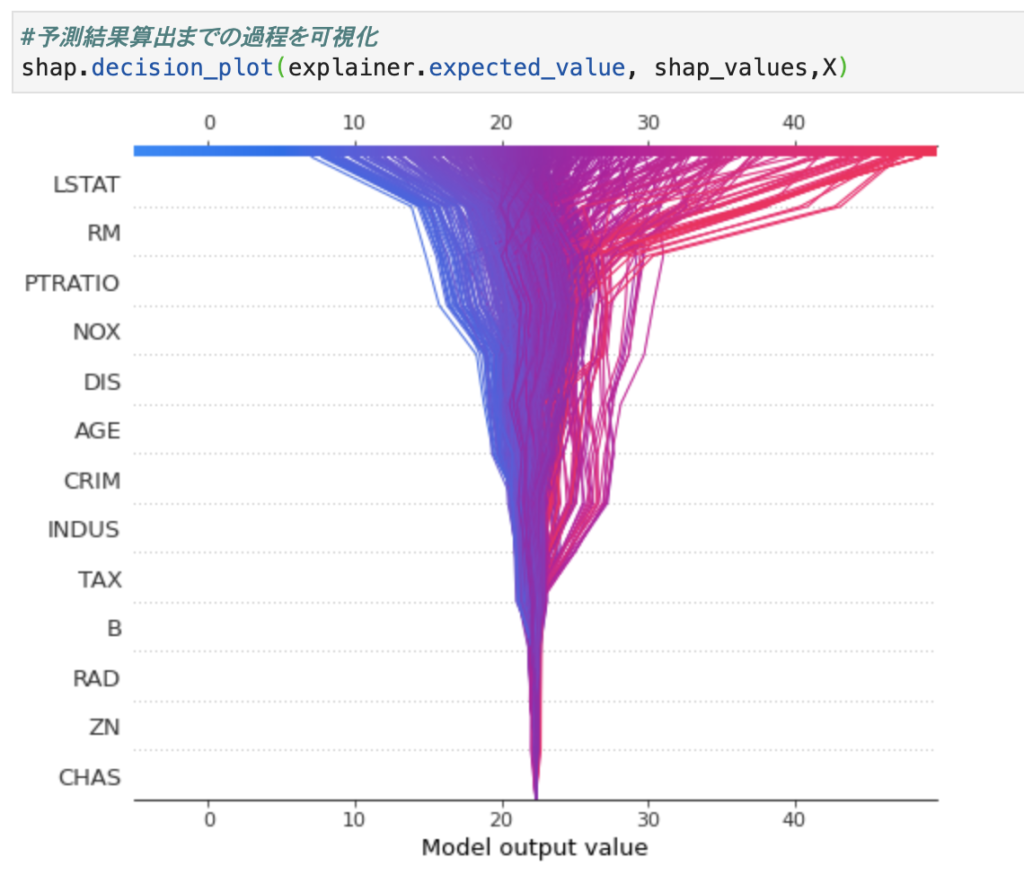
下段に記載されているCHAS,ZN,RADはほとんど予測に寄与していないことがわかります。
Bで若干数が下振れ、上振れに変化し、以降の特徴量は予測に寄与していることが伺えます。
予測精度が非常に高く予測される人はRMで急激に増加していることがわかります。
下振れはLSTATの影響が大きく、徐々に減少していき最後にガクッと下がっていることが伺えます。
個別の特徴量について少し深掘りしてみましょう。
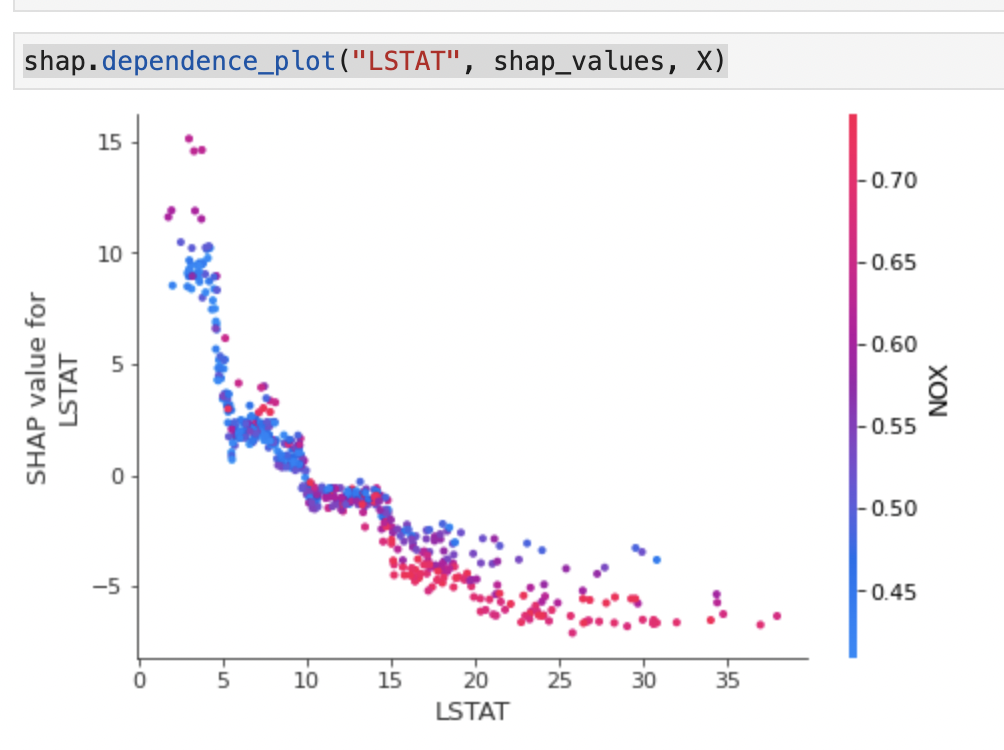
縦軸がshap値、横軸がLSTATの値となっています。
LSTATが高いほどshap値は低くなっていることがわかリマス。
色は交互作用が一番はっきりと表れる変数が自動で選択されます。
NOXが大きいほど赤くなっており、同じLSTATの場合、NOXが大きいほどshap値が小さくなることがわかります。
○まとめ
RMなど予測に効きそうなことは直感的にわかるが、実際に何部屋から予測に寄与するかなどをfeature_importancesから読み取ることは難しいためshapを使用することで、各特徴量の値の変化による予測への寄与度を簡単に可視化出来ることは予測に寄与する特徴量を探索していく上で有効だと感じた。
特に、機械学習を用いて業務改善などを行う場合など、予測値そのものよりどのような因子が影響しているのかが重要となるような場面に非常に有効だと感じました。まだまだ、さわり部分しか使っていないため解釈の仕方や可視化の方法などもっと学習していきたいと感じた。
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
コメントを残す