BERTによる歌手分類(ファインチューニング)
今回は以前実施したBERTを使用した歌手分類の精度向上のため、ファインチューニングを実施します。
前回の記事は下記のURLから閲覧できます。
https://techstudyoutgoing.com/%e8%87%aa%e7%84%b6%e8%a8%80%e8%aa%9e%e5%87%a6%e7%90%86%ef%bc%9abert%e3%81%ab%e3%82%88%e3%82%8b%e6%ad%8c%e6%89%8b%e5%88%86%e9%a1%9e%e3%81%ae%e5%ae%9f%e6%96%bd/
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
○BERTとは
Bidirectional Encoder Representations from Transformer(Transformerによる双方向のエンコード表現)
現在の自然言語処理コンペなどではよくBERT、Robertaなどが使用されており高い精度を出しています。
○ファインチューニングとは
既存の学習モデルの一部と、新たに追加した学習モデルを合わせて微調整することです。学習済みのモデルをそのまま利用しても自分が解きたい問題や持っているデータの性質によって精度が出ないことがあります。その際に、自身の持っているデータを使用して学習済みの重みを微調整することで精度を向上させる手法です。
○では、早速実践していきます。
モデル学習部分までは先ほど掲載させていただいた過去の記事に記載があります。そのため、今回は過去のコードとは異なる点を記載していきます。
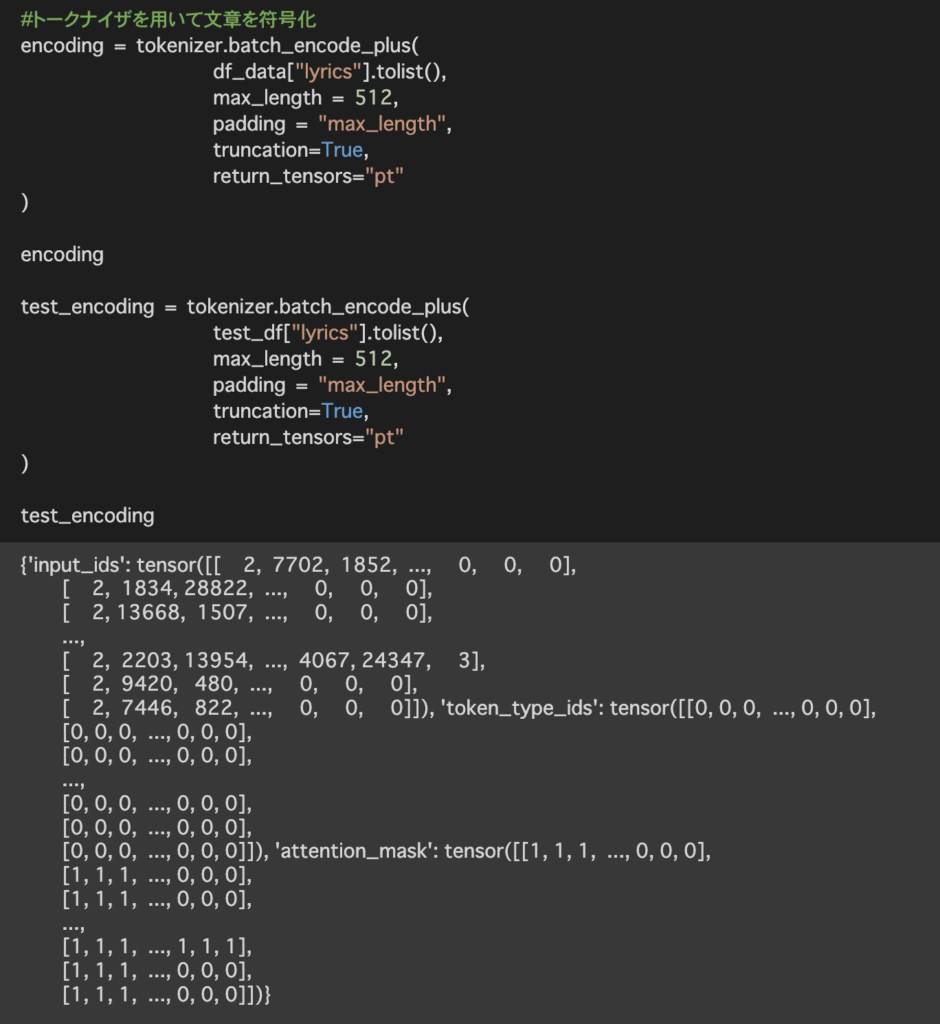

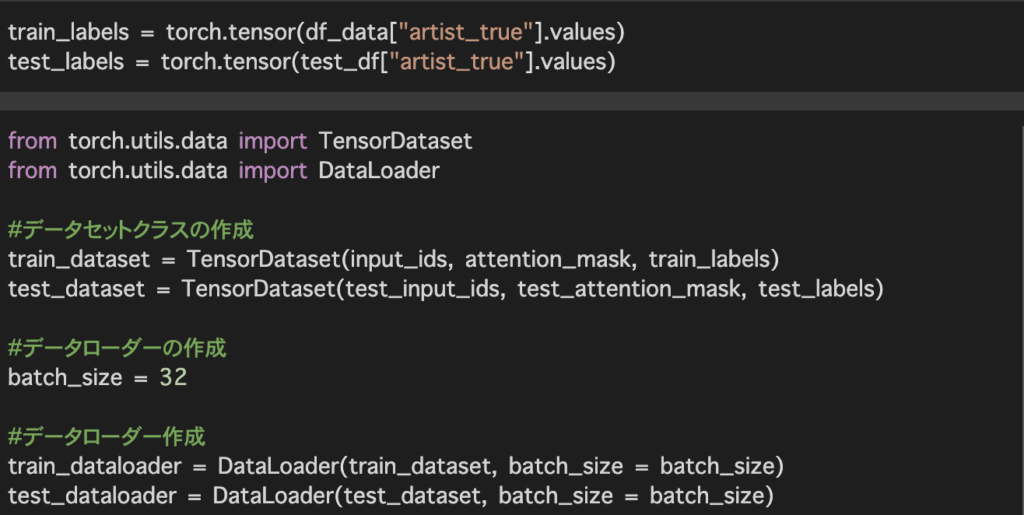
作成したデータセットを元にデータローダーを作成します。データローダーを作成することによって配列ではなくイテラブルとなり、For文等でデータを取り出すことが可能となります。
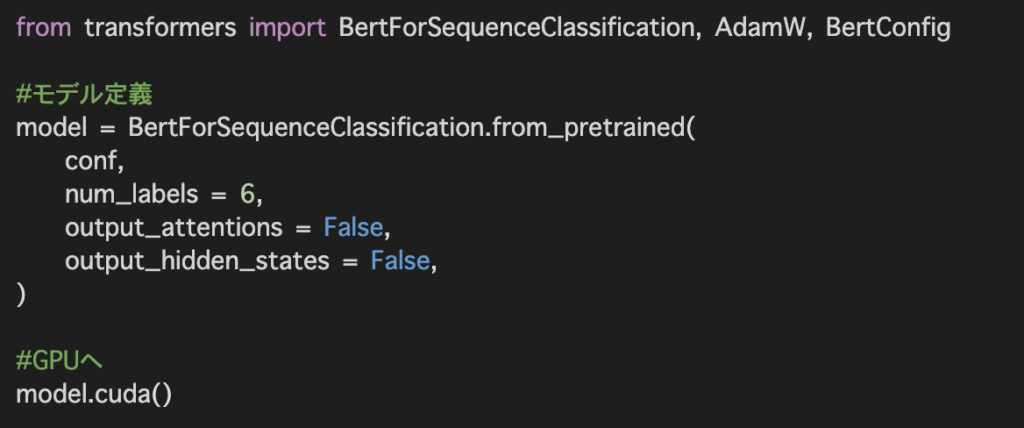
今回は歌詞を元に6種類のアーティストに分類するためnum_labelsを6とします。こちらの数を分類したい数に変更することで2値分類、多分類にも対応できます。
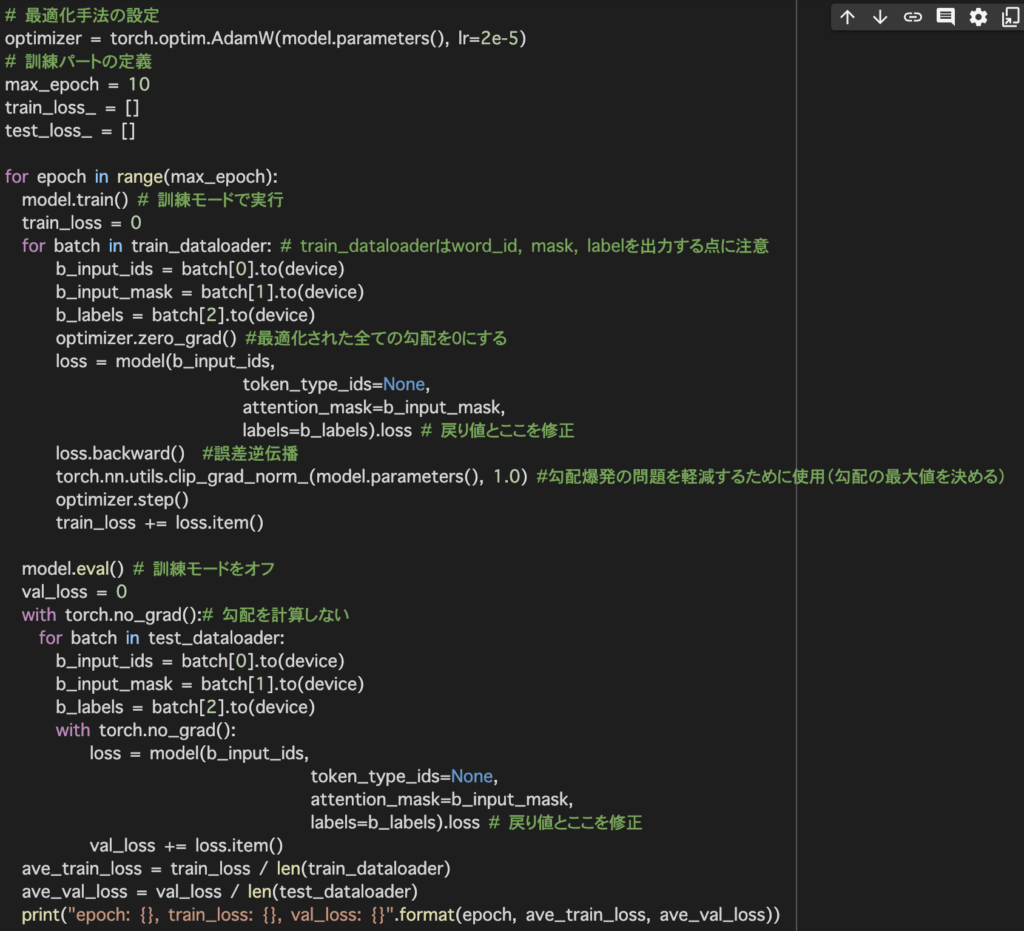
optimizer.zero_grad()で最適化された全ての勾配を0にし、学習を行います。
その後、loss.backward()で勾配を計算します。
最後にoptimizer.step()でパラメータを更新します。
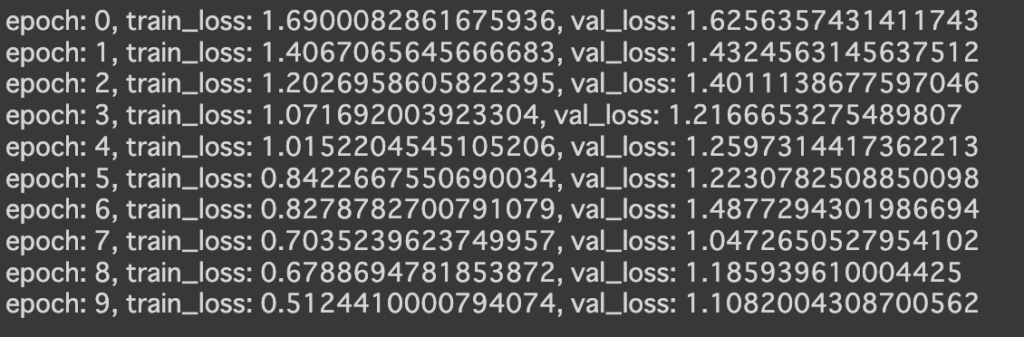

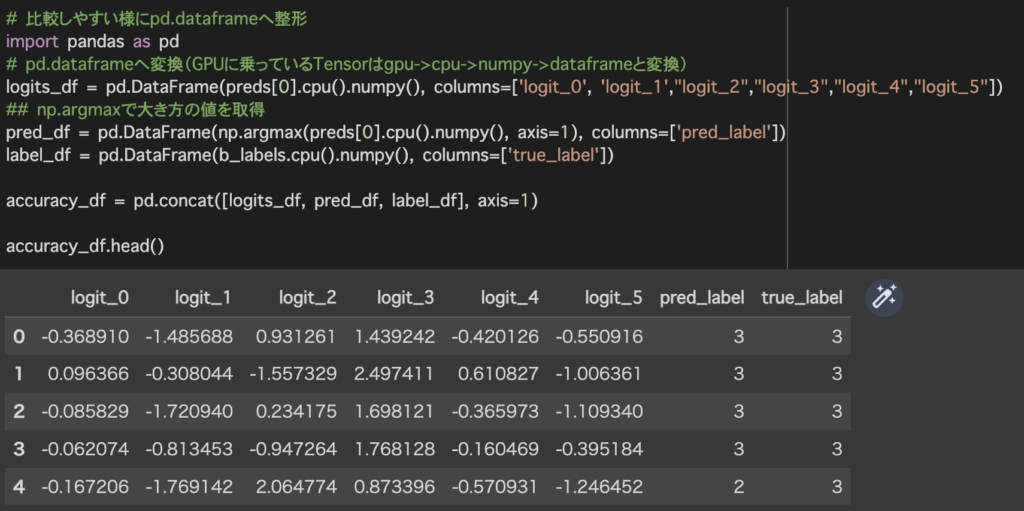
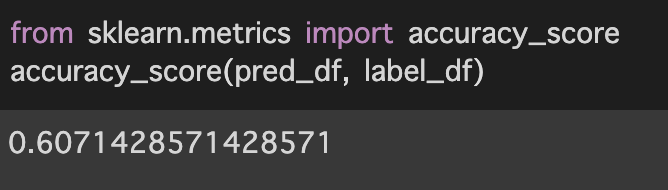
今回は60.7%で予測結果と真値があっていました。
元々、前回の精度が18.8%だったことを踏まえるとファインチューニングによって大幅に精度が上がりました。
○まとめ
数行でBERTなどを実行できるからこそ、ただ実装するのではなく、いかにモデルの実力を最大限発揮できるよう解きたい問題・手元にあるデータの性質に合わせてチューニングするかが重要ということを改めて実感しました。
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
○参考サイト
自然言語処理モデル(BERT)を利用した日本語の文章分類:https://qiita.com/takubb/items/fd972f0ac3dba909c293
コメントを残す