AmazonBookレビューデータを用いたレコメンド実装
Amazon Bookレビューデータを用いて類似商品を推薦するレコメンドを実装してみたいと思います。今回はコサイン類似度を用いて行います。
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
今回使用したデータ:https://www.kaggle.com/datasets/mohamedbakhet/amazon-books-reviews
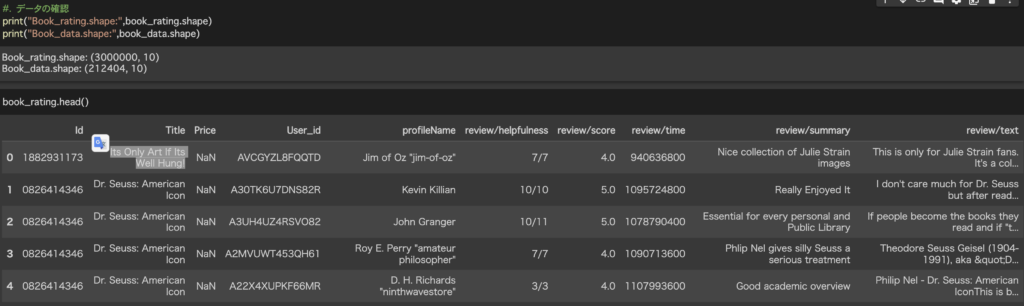
・Books_rating
212,404冊のユニークな本に関するフィードバックが含まれている。
期間は1996/05から2014/07
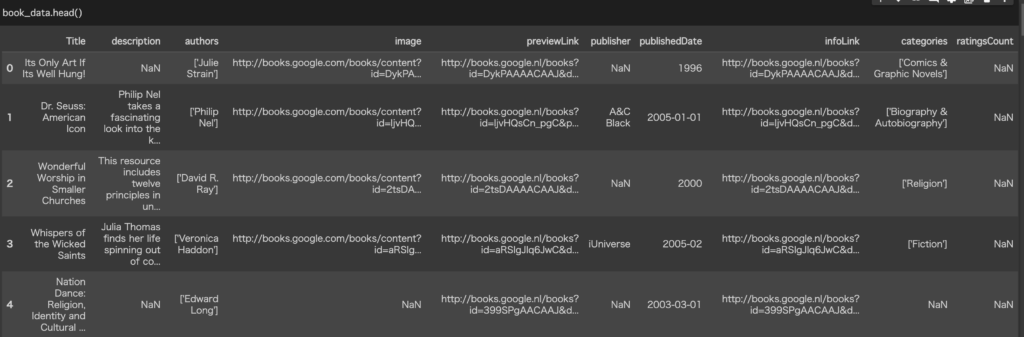
・books_data
212,404冊のユニークな本に関する詳細情報
○レコメンドとは
英語でrecommendと書き「推薦、お勧め」という意味通り自分の購買情報や属性などを元に商品などをお勧めしてくれる仕組みです。AmazonやNetflix、zozoなどを使用したときに「あなたにオススメの商品・映画」と記載付きで紹介された経験があると思います。このような仕組みをレコメンドと言います。
○推奨システムの種類
推奨システムの主な2つを紹介します。
1.協調フィルタリング:ユーザーのwebアクセス履歴や行動属性に基づいて商品をレコメンドする手法です。
2.コンテンツベース・フィルタリング:商品にユーザーの評価などの情報を付与して特徴が似ている商品をレコメンドする手法です。
今回はコンテンツベース・フィルタリングを実装します。商品の特徴としてレビューを特徴量としてコサイン類似度で類似商品を抽出しようと思います。
レコメンドについてはALBERTの記事がわかりやすかったので詳細を見たい方は下記のリンクを見ていただくといいと思います。
https://www.albert2005.co.jp/knowledge/marketing/recommendation_basics
○実装
それでは実際にコードを書いて実装していきます。
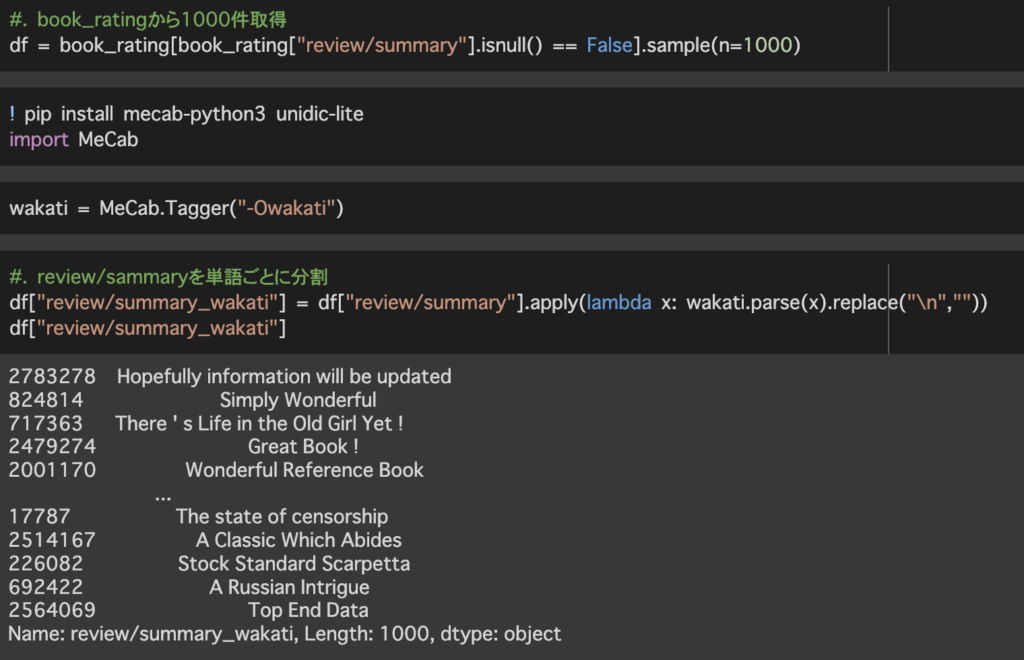
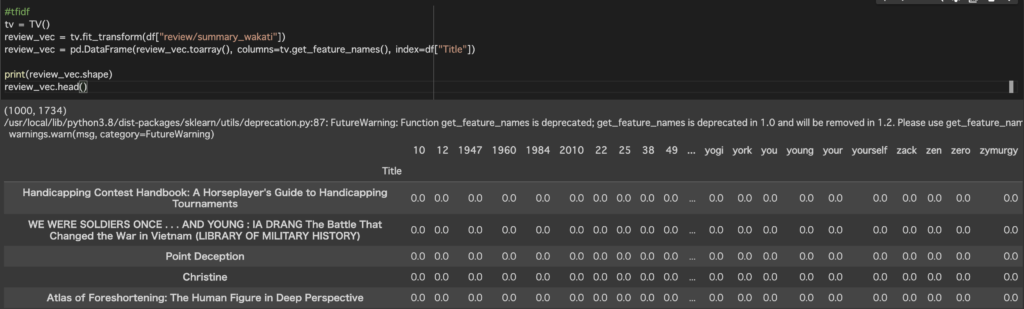
review/summaryを用いてレコメンドをしてみようと思うのでreview/summaryをtfidfでベクトル化できるように単語ごとに分割します。

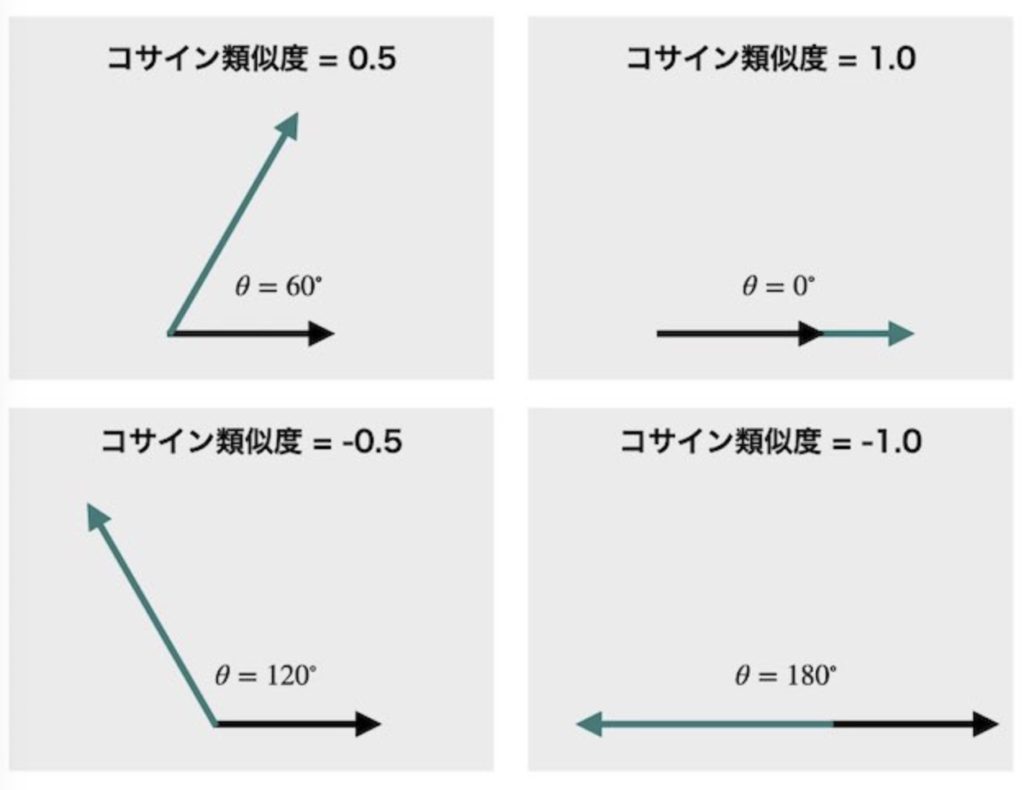
上記の図が非常にわかりやすかったため引用させていただきました。コサイン類似度は-1~1までの値をとり、向きが近いほど1に近づいていきます。つまり、1に近いほど2つの商品は似た商品と判断できます。
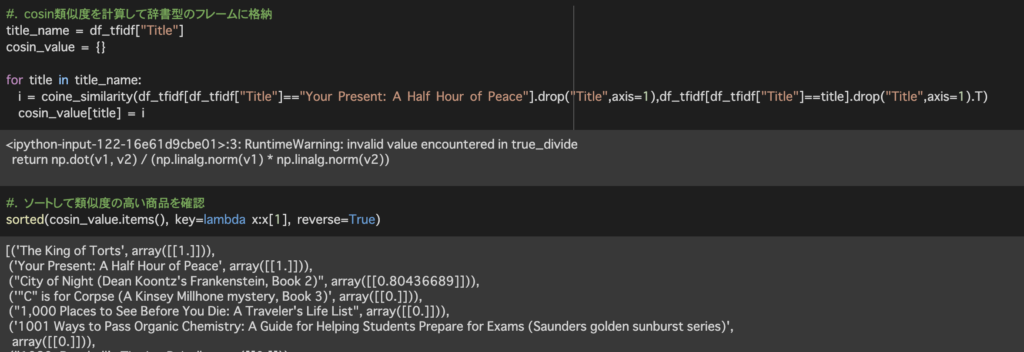
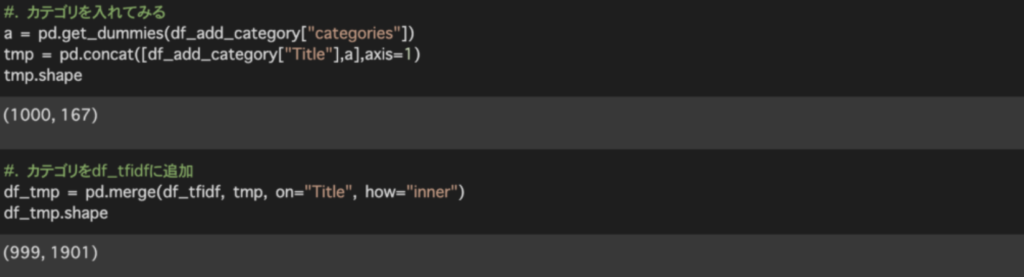
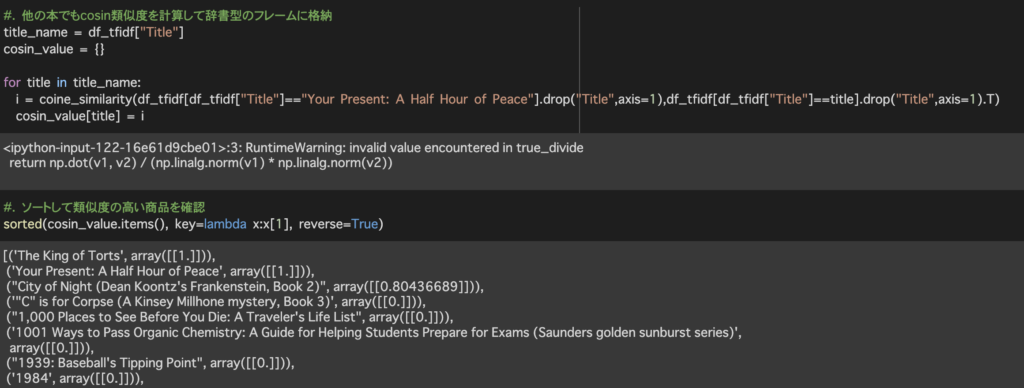
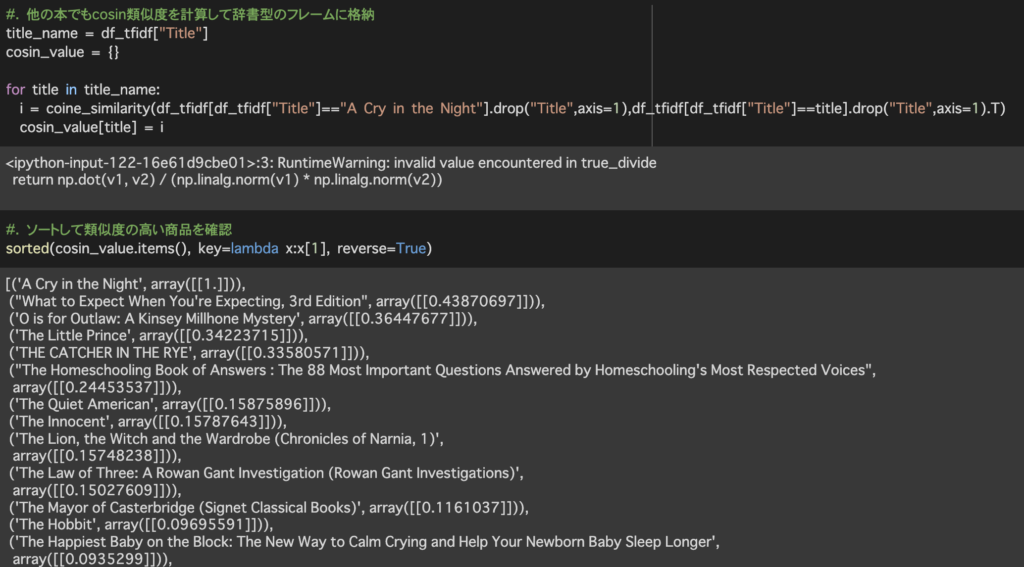
計算結果は辞書型で{タイトル:類似度}のような形で格納されるよう処理しています。
sorted(cosin_value.items(), key=lambda x:x[1], reverse=True)で辞書型に格納したデータを類似度の降順に並べ替えています。
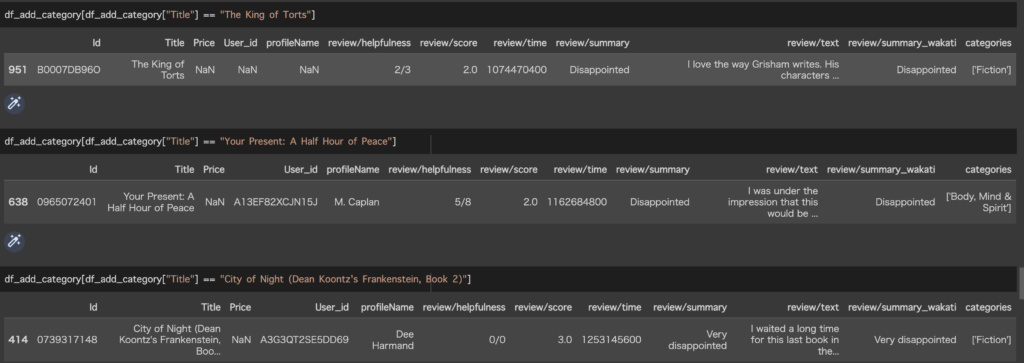
今回の結果では[The King of Torts]、[City of Night~]がコサイン類似度が1に近く似ている商品として出力されました。それ以外は0と出力されています。
○まとめ
今回はコサイン類似度を計算してレコメンドを実装してみました。レビューに出てきた単語を特徴として利用したのですが精度が低い結果となりました。レビューを利用していたためデータ数を1,000件にサンプリングしたことにより商品の本質を捉えきれなかったのではないかと考えています。今度はデータ数を増やしたり、その他の特徴量を検討して精度を上げたいと思います。
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
○参考サイト
キヨシの命題:https://yolo-kiyoshi.com/2020/08/26/post-2234/#outline__2_4
ALBERT:https://www.albert2005.co.jp/knowledge/marketing/recommendation_basics
コメントを残す