歌詞データのスクレイピング方法
今回から3回に分けて歌詞データを用いた歌手分類や自分の好きな曲の特徴を探索したりしていきます。1回目は歌詞データを用意するためのスクレイピング方法になります。
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
○今回使用したサイト
Uta-Net:https://www.uta-net.com/artist/9369/
○参考にさせていただいたサイト
https://zatsugaku-engineer.com/python/scraping/
○github(今回使用したコード)
https://github.com/ryosuke-yakura/lyrics_classification
スクレイピングに使用したコードは下記になります。
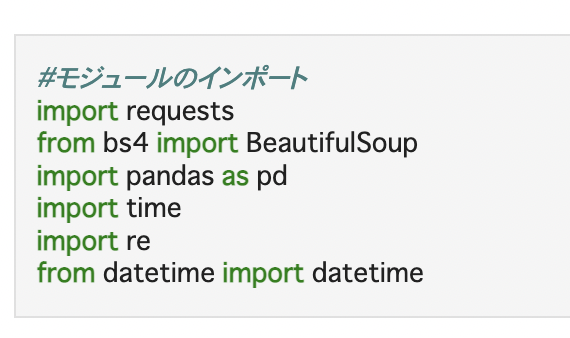
BeautifulSoupを利用することで簡単にデータを取得できます。
○今回の手順
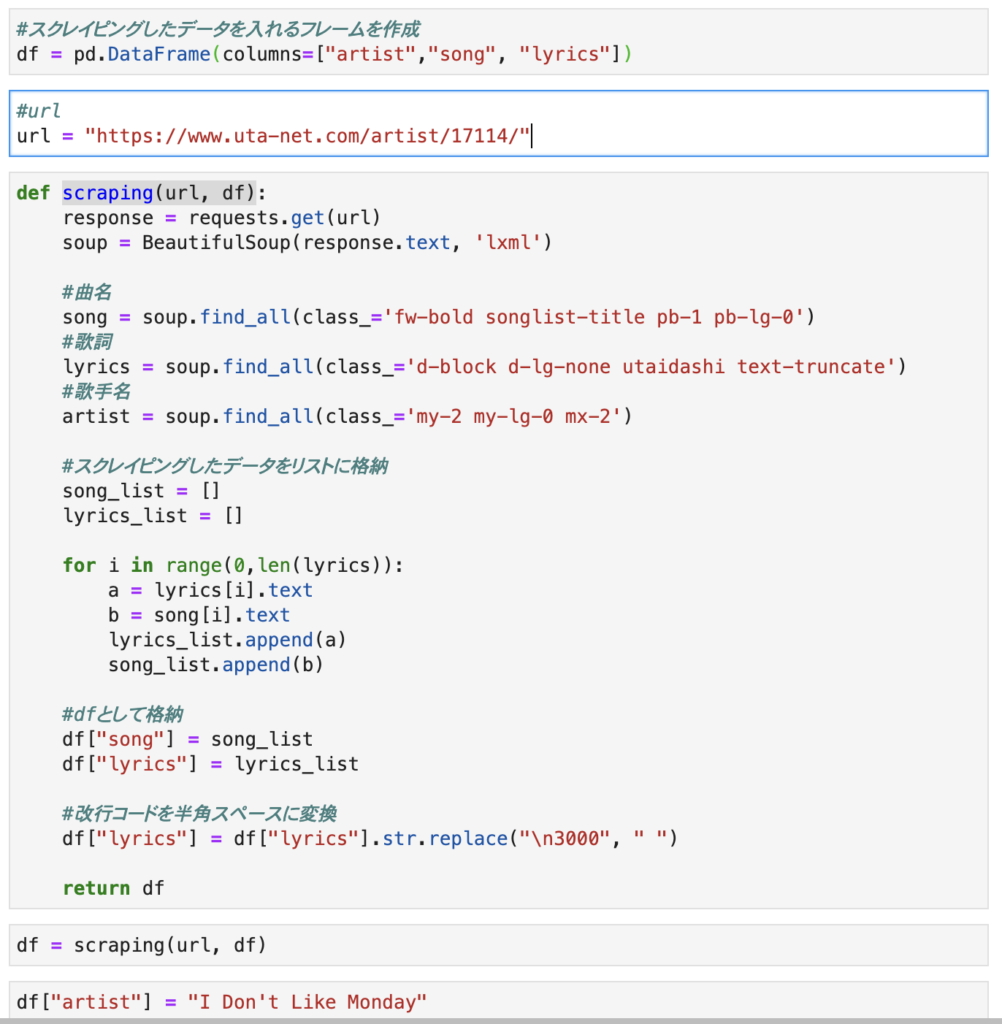
1.スクレイピングしたデータを格納するデータフレームを作成
df = pd.DataFrame(columns=[“artist”,”song”, “lyrics”])
今回は歌手名、曲名、歌詞の3つのデータを取得したかったため、上記データフレームを作成。
2.取得したいページの情報を取得
url = “https://www.uta-net.com/artist/17114/”
response = requests.get(url)
soup = BeautifulSoup(response.text, ‘lxml’)
まず取得したいwebページのURLを変数に入れます。
次にrequests.get(url)でurlのページ情報を取得します。
最後に取得したページ情報をBeautifulSoupに渡してあげます。
BeautifulSoupでは必要な箇所を指定、検索する方法が複数あります。ここでは言及しないためGoogleで検索していただくとわかりやすい解説が沢山あると思います。
3.曲名、歌詞を取得
song = soup.find_all(class_=‘fw-bold songlist-title pb-1 pb-lg-0’)
lyrics = soup.find_all(class_=‘d-block d-lg-none utaidashi text-truncate’)
一つ目のコードで曲名、2つ目で歌詞を取得しています。
soup.find_all(class=’class名’)で指定したクラスに記載されている内容を取得できます。
欲しい情報がどこにあるかはGoogleの検証機能から探す必要があります。
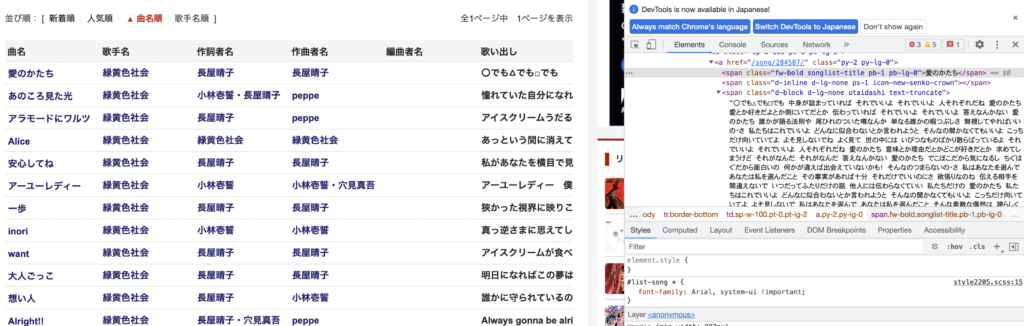
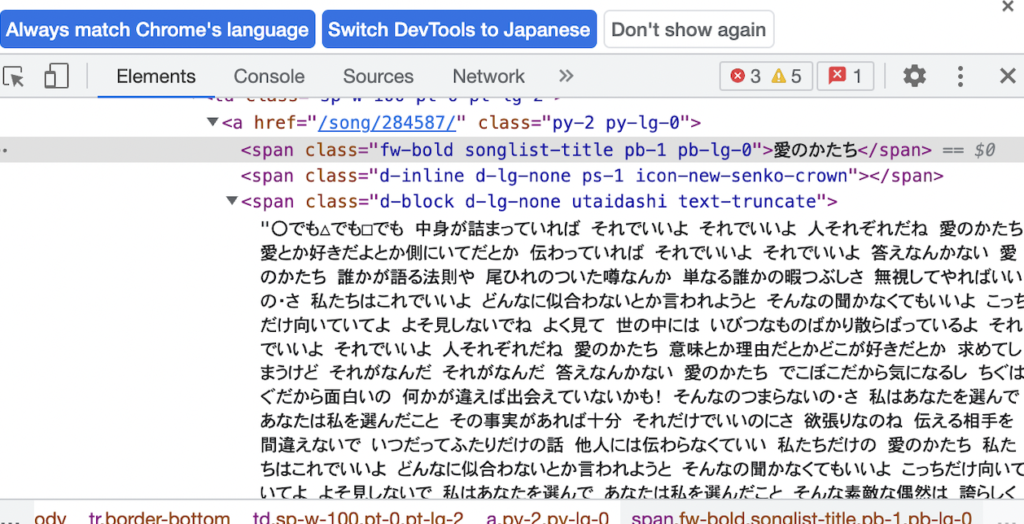
今回のサイトではコードの上から2番目に当たる部分に<span class=”fw-bold songlist-title pb-1 pb-lg-0″>愛のかたち</span>と記載されているのがわかると思います。こちらが曲名が記載されているclassになるためsoup.find_all(class_=‘fw-bold songlist-title pb-1 pb-lg-0’)でclassを指定することで曲名のみを取得しています。
4.取得したデータをデータフレームに格納

先ほど3で取得したデータはそのまま使用するとHTML構文まで一緒についてくるため.textを後につけてあげてtextのみを取り出します。
その後、あらかじめ用意しておいた空のリストに.appendで追加し、最後に1.で作成したデータフレームに格納しています。
※もっと簡単に行う方法もあると思います。
1点注意点があり、歌詞など長い文章を取ってくると改行されていることがあります。
下記はスクレイピングし、.textで表示させた歌詞になりますが\u3000という改行コードが記載されています。

今回は歌詞をスクレイピングする方法を記載しました。一から手入力したり、コピーするのは大変ですがスクレイピングならすぐに取得が出来るため便利です。しかし、サイトの中にはスクレイピングを禁止しているサイトもあるため注意が必要です。
次回は作成したデータを用いて歌詞から歌手分類を行います。
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
コメントを残す