自然言語処理:Bertによる歌手分類の実施
今回は前回実施した歌手分類の精度向上を目的にBertによる歌手分類を実施します。
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
○今回使用したコード
github : https://github.com/ryosuke-yakura/lyrics_classification
○Bertとは?
Bidirectional Encoder Representations from Transformer(Transformerによる双方向のエンコード表現)
RNNなどではそれぞれの層の中で文章の前方から順々に処理が行われ、処理を経るにつれ前方にあるトークンの情報を失っていましたが、Bertではトークンを処理する際に、他のトークンの情報を直接参照し、トークンの情報にどの程度注意を払うかを決めることで文脈に応じた処理が可能となっています。
現在の自然言語処理コンペなどではほとんどがBert、Bertの派生系であるroberta、debertaが使用されることが多いほど他のモデルと比べて精度が高いです。
では実際にBertを使ってみましょう。
Bertでは基本的に事前学習モデルを使用します。
事前学習モデルとは企業などが大量のデータを学習し作成したモデルになります。
この事前学習モデルを使用することで大量の学習を行わなくても精度の高い予測が可能となります。

transformersとはHugging Face社が作成したライブラリになります。
Bert学習に必要なトークナイザ(下で説明)などBertに必要な処理を簡単に行えるライブラリになります。
AutoTokenizerといった何にでも使用可能な万能なものもあります。
※トークナイザはトークナイザ処理を行う部分で説明します。今はBertを使用するために必要な処理の一つと認識してください。
学習にはGPUを使用する必要があります。google colaboratoryでは無料でGPUを使用できるためgoogle colaboratoryで実行するのがオススメです。
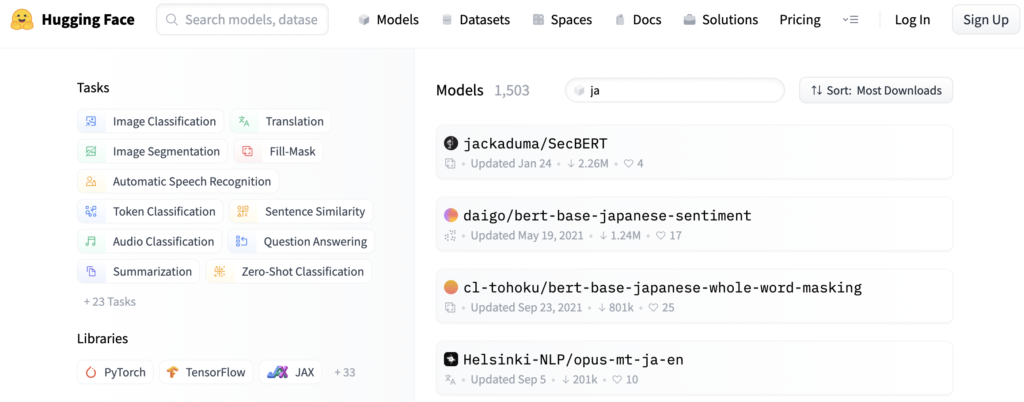
事前学習モデルは下記の画像にあるHugging Face(https://huggingface.co/)より用途に合わせて選択します。modelsの検索部分にjaと入力すると日本語版事前学習モデルが検索できたりします。
事前学習モデルにより必要な環境が異なり、今回使用した事前学習モデルではfugashi、ipadicが必要でした。事前学習モデルの説明文を確認するか、エラーでインストールが必要なものはエラー内容に記載されているためエラー内容を確認しライブラリをインストールしてください。
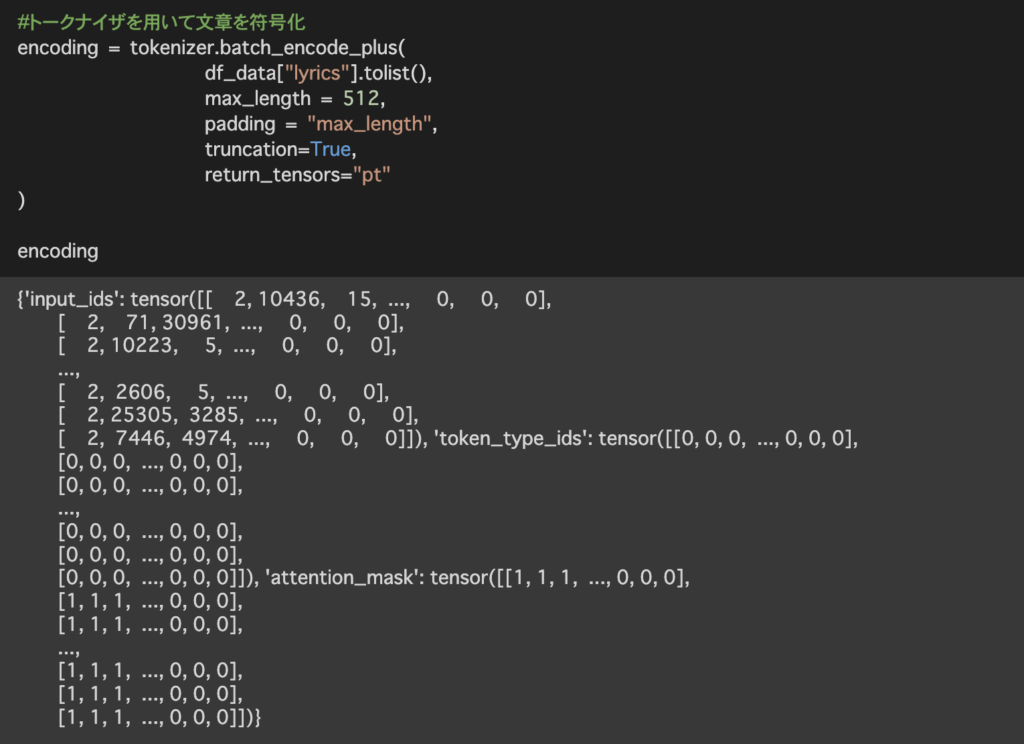
トークナイザとは文章をトークンに分割し、Bertに入力できる形に変換するためのものになります。
テキストをトークナイザすると出力結果のような形になります。
ちなみにmax_lengthは最大512になります。こちらの数値は文頭から何文字までを取ってくるかを示しています。重要な内容が文頭と文末に記載されている場合などは、ここの取得方法を文頭から250、文末から250文字といった形で分割したりすることで精度の改善が見込まれます。
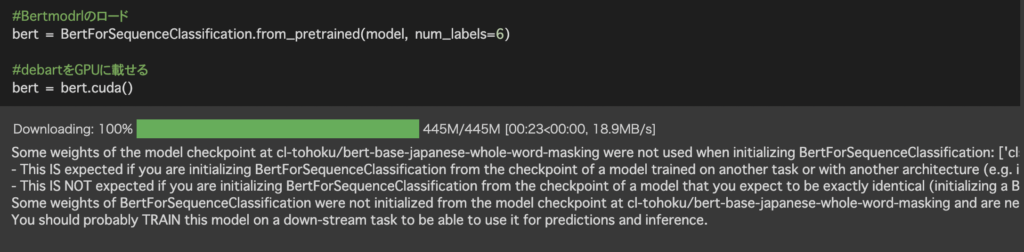
引数のnum_labelsに正解ラベルの数を入れてあげます。
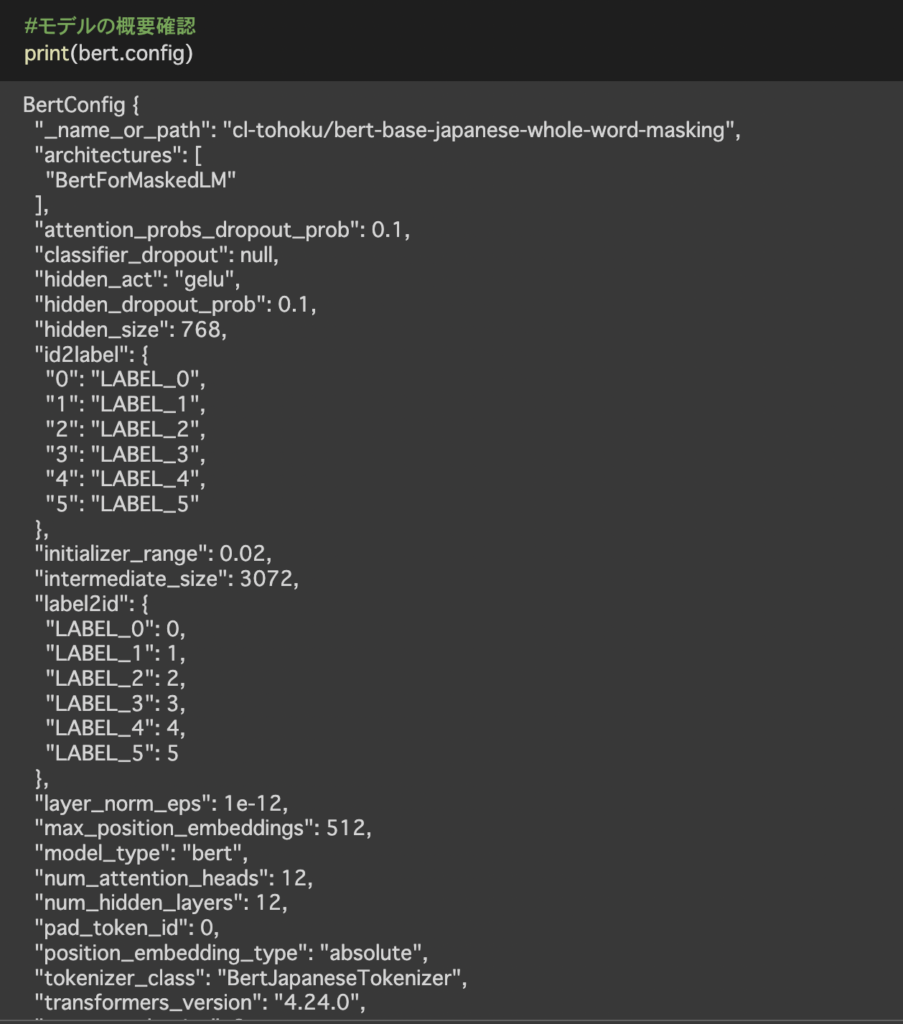
主な値としてここでは3つ挙げさせていただきます。
num_hidden_layers レイヤー数は12
hidden_size 出力は768次元
max_position_embeddings 最大で入力できるトークン列の長さ512

トークナイザ、学習は前で記述したコードと同一のため省略させていただきます。
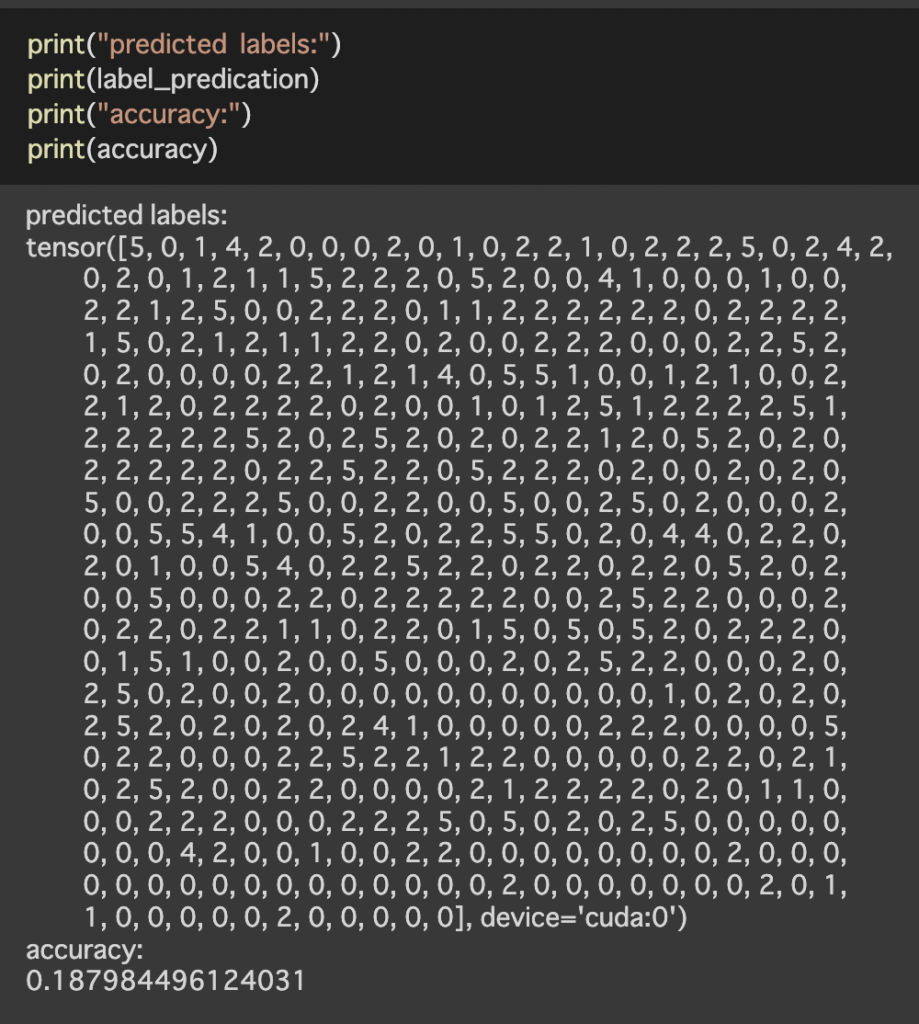
○まとめ
今回は前回lightgbmを使用した歌手分類をBertで実施してみました。自然言語処理にはBertが有効という頭があったため、精度が上がることを期待していましたが結果としては精度は下がりました。一番の要因として考えているのは今回、文頭から512文字をトークナイザし使用しているため、歌詞のような文字数の長いものに対しては512文字の取得方法を検討する必要があると感じました。(サビを持ってくる、Aメロ、Bメロ、サビなどでデータを分割しても良いかも?)データ数が少なく、かつ文章が長い場合は文章をベクトル化し、lightgbmを使用するという手法も念頭に置いて色々と試してみることが重要と感じました。
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
○参考サイト、書籍
書籍 BERTによる自然言語処理入門:Transformersを使った実践プログラミング
サイト Hugging Face
1件のコメント