自然言語処理:歌詞データから歌手分類
今回は前回作成した歌手データを使用して歌手分類を行います。ベクトル化にはCountVectorizer及びTfidfVectorizerを使用します。
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
○自然言語処理の流れ
自然言語処理では文章を機械が学習できるように数値に変える必要があります。
基本的な流れは文章の分かち書き(文書を語句で区切る)を行い、語句をベクトル化することで数値に変えます。
○ベクトル化(CountVectorizer、TfidfVectorizer)とは
語句を機械が学習できるように数値に変える手法です。
CountVectorizer:単語の出現数をカウントする手法
TfidfVectorizer:単語の出現頻度と特定の文書に頻出する単語の出現頻度を掛け合わせた手法
上記なもの以外にもBertなどもベクトル化が可能です。
○分かち書きとは
文章を指定した単位ごとに区切りその間にスペースを置くことです。
○github:https://github.com/ryosuke-yakura/lyrics_classification
○歌手分類を実施
では、まずはデータを確認します。

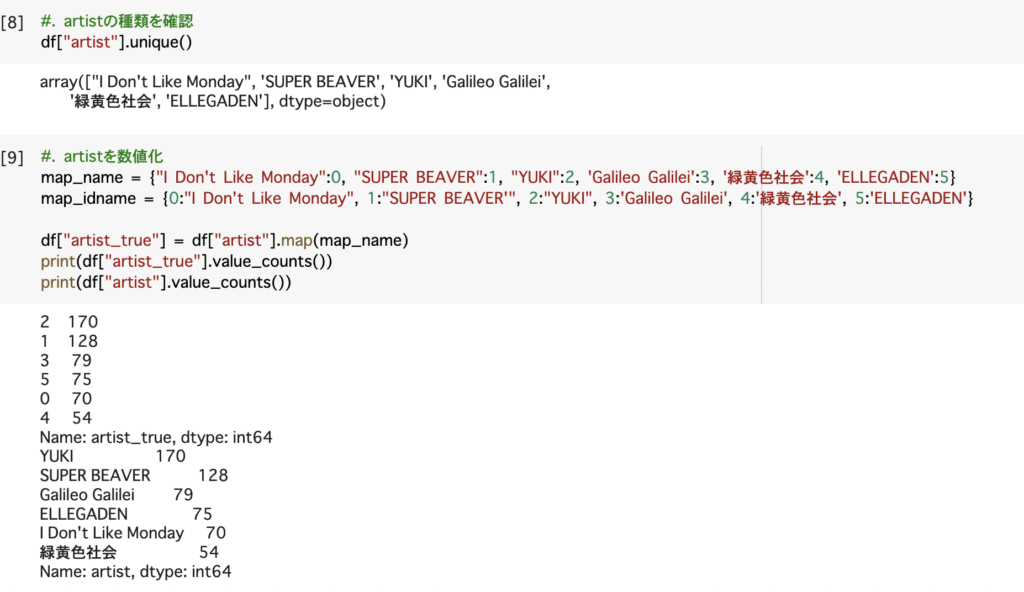
今回は6つのバンドに歌詞を元に分類していきます。
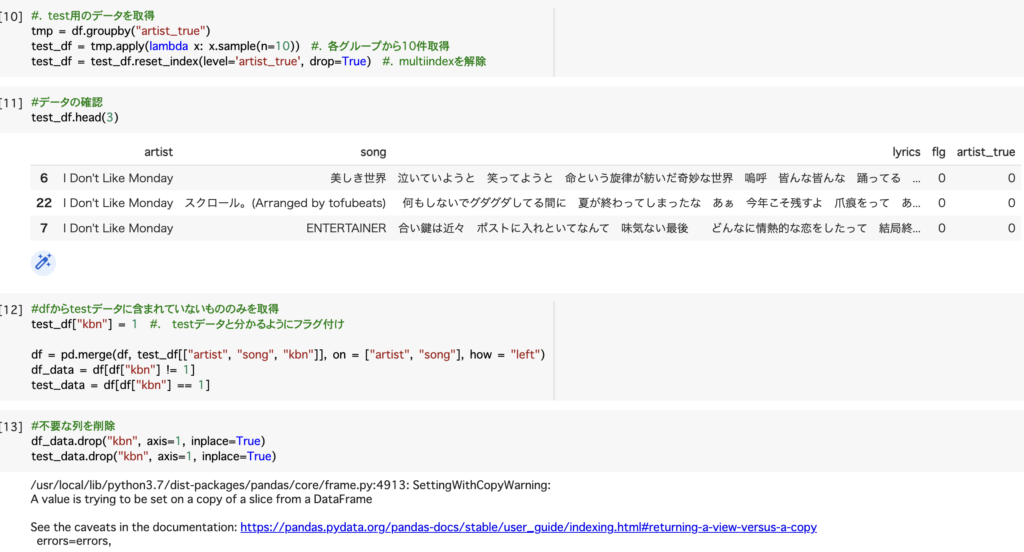
今回は各歌手毎に10件ランダムサンプリングしています。
グループ毎に抽出する場合はgroupbyを使用すると簡単に抽出が可能です。
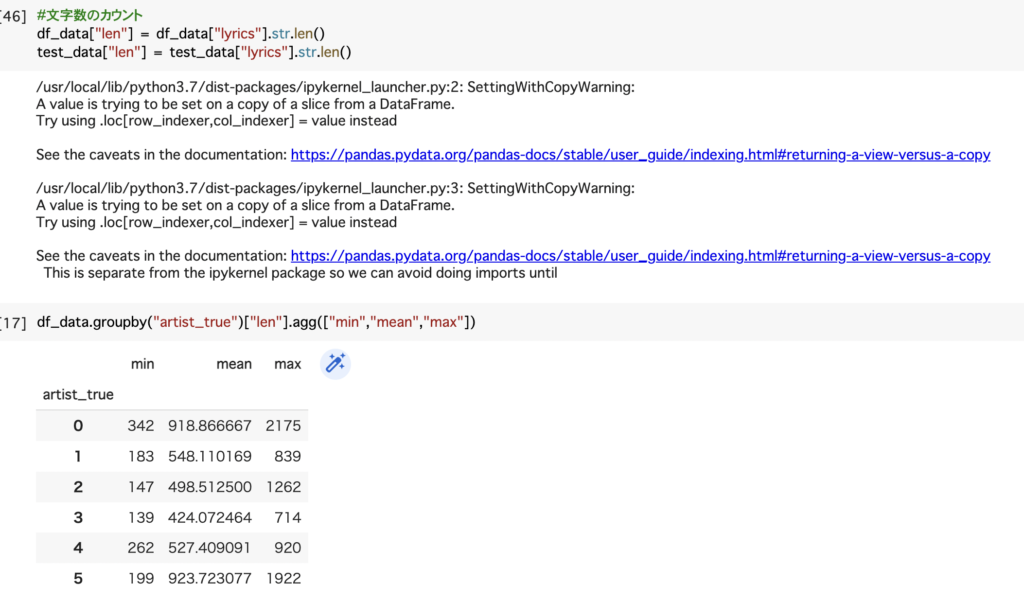
2(YUKI)、3(ガリレオガリレイ)は短いと100文字代、長くても714文字と文字数が少ないが、一方で0(I dont like monday)は長いのは平均が一番高く、最大値も2,000以上となっています。
では、本題に入っていきます。まずは分かち書きを行い文章を語句に区切ります。
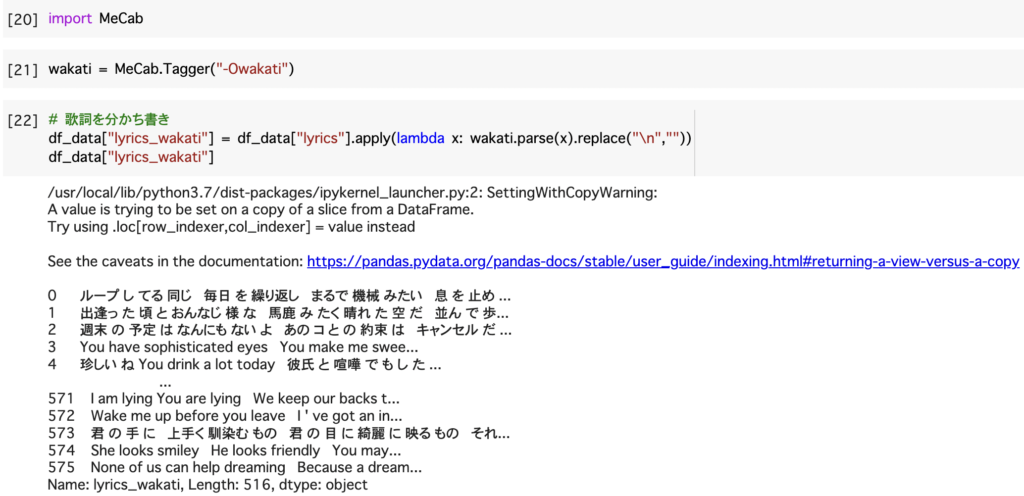
dfをそのまま分かち書きすることはできないため、lambda関数を用いて処理を行います。
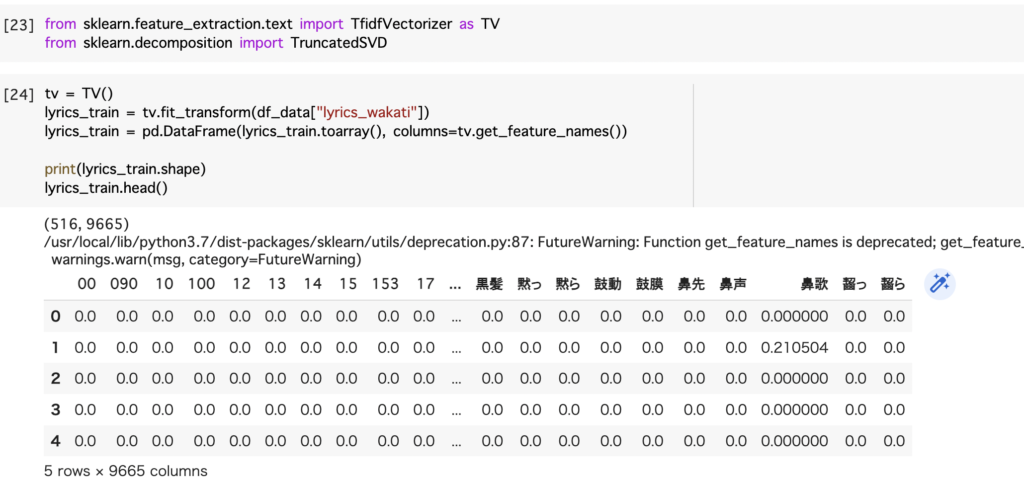
分かち書きした語句に対してベクトル化を行います。
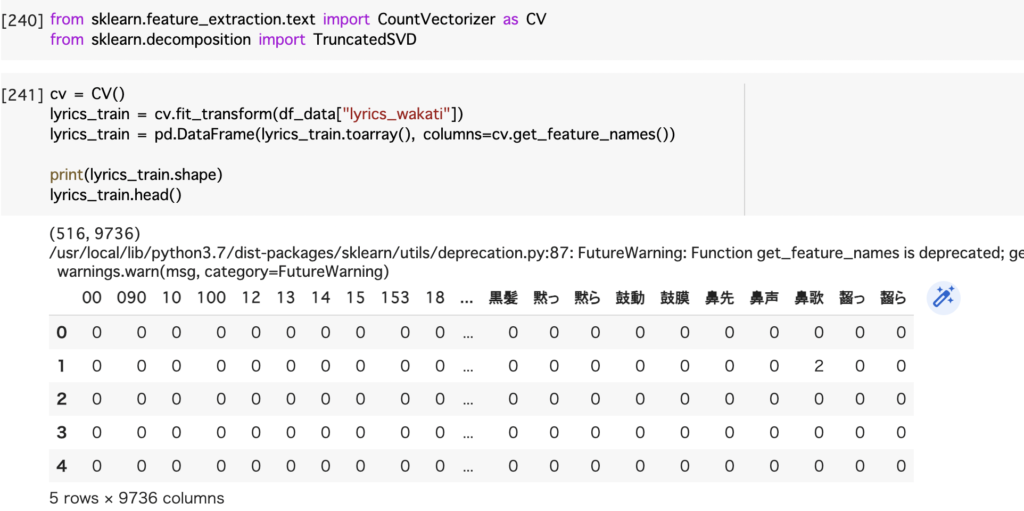
使用すると上記のような行別に各単語の出現頻度をカウントしたものが出てきます。
ベクトル化をしたものを使って学習します。
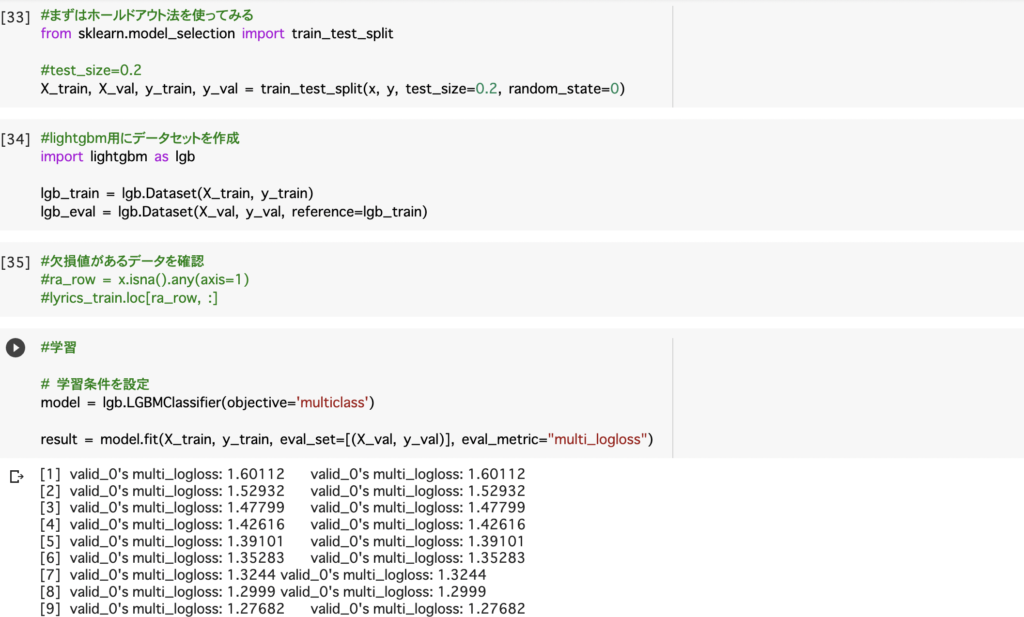
結果が下記になります。
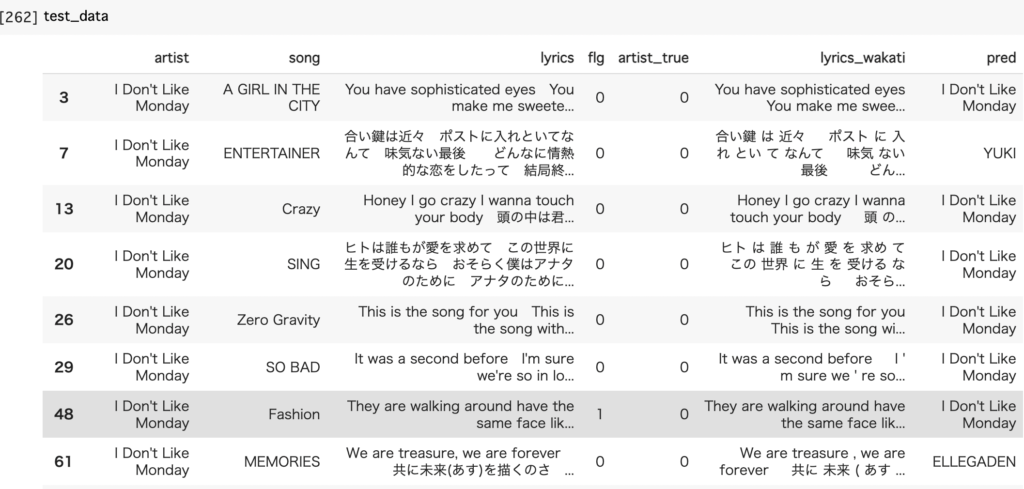
最初の8件を確認してみましたがちょこちょこ間違って分類がされています。
○次はTfidfVectorizerを実施します。
基本的にはCountVectorizerと変わりません。
実際に先ほどと同じ条件で学習を行ってみます。
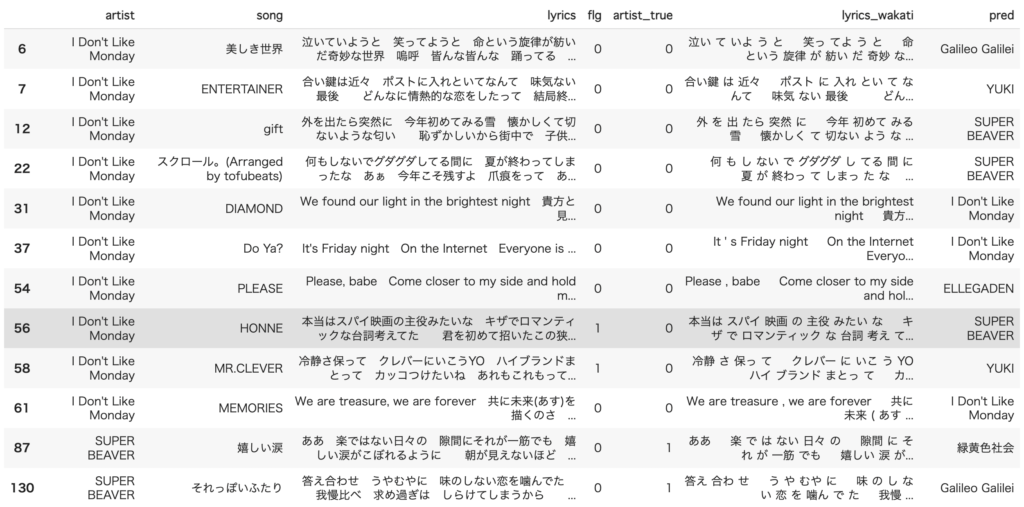
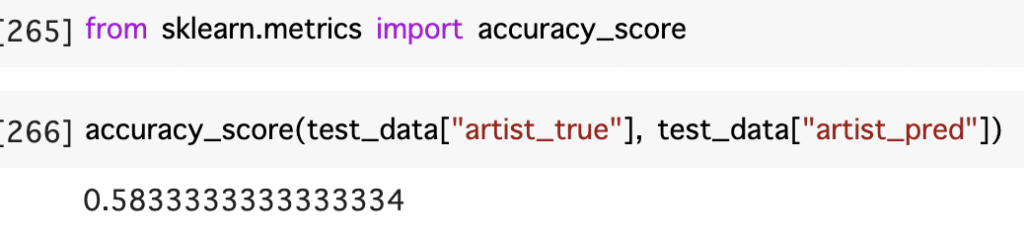
ほとんど予測できていないことがわかります。上記には載っていませんがYUKI、SUPER BEVER、ELLEGADENはほとんど予測できていました。
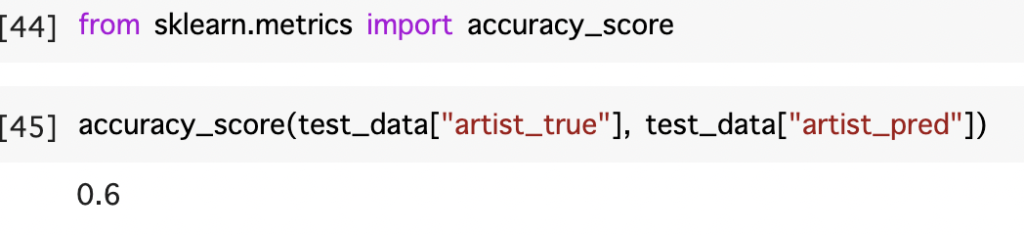
今回はCountVectorizerとTfidfVectorizerを利用した歌手分類を行いました。
精度は6割とデータ数が少ない中では割と良い精度なのではないかと感じた。
精度を上げるには、Bertやデータ数を増やすこと、前処理の実施などが考えられる。
分類のみではなく、ベクトル化した出現頻度などを可視化することだけでも有用な知見を得れると感じた。
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
コメントを残す