多重共線性(マルチコ)の対処方法を検討してみた
今回はsklearn.datasetの一つであるbostonのデータを用いて、マルチコを実際に起こして対処方法を検討してみました。
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を目的としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
今回使用したコードは下記のURLから確認できます。
github:https://github.com/ryosuke-yakura/Multicollinearity
○マルチコについて
マルチコとは説明変数に相関係数が高い組み合わせが存在することを言います。これの何が問題かというと、予測をする上で異常値を取ったり説明変数が目的変数に与える影響が変な挙動をしたりします。例えば、目的変数をある商品の今月の販売点数、説明変数をある商品の前月の販売点数、2ヶ月前の販売点数、3ヶ月前の販売点数とします。説明変数に使用している特徴量はいずれも相関が高そうです。このモデルで予測した際に、データの分布では各特徴量が高い方が販売点数が上がっているのに、各特徴量が目的変数に与えている影響を確認すると、前月の販売点数が多いほど今月の販売点数が高くなる、反対に2ヶ月前の販売点数は高いほど低くなるなどの挙動を示すことがあります。これがマルチコは解消しないといけないと言われる理由の一つです。
○マルチコの確認方法
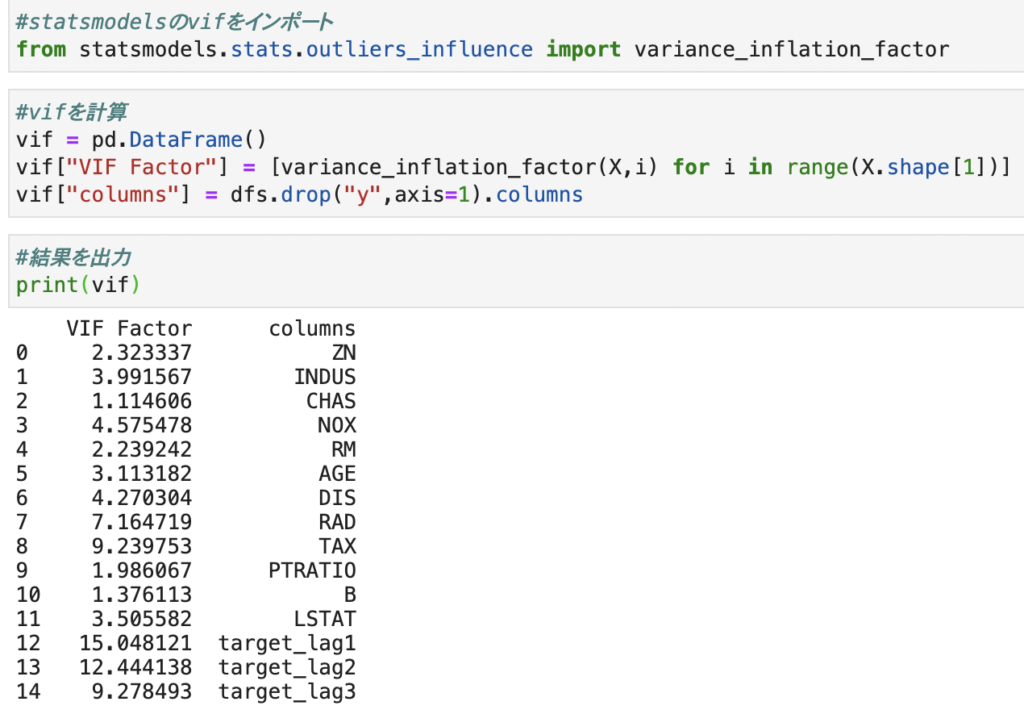
1.相関行列を確認(0.9以上)
2.vifを確認(明確な基準はないがおおよそ10以上と言われている)
○マルチコの解消方法
1.他の変数と相関の高い変数を削除する、正規化を行う
2.主成分分析を行う
主に上記の2パターンが対処法となります。
今回は上記の2つを試して精度が改善するのか検証してみます。
今回は擬似的に相関の高い変数を作成します。

相関係数はそれぞれ0.9以上となります。
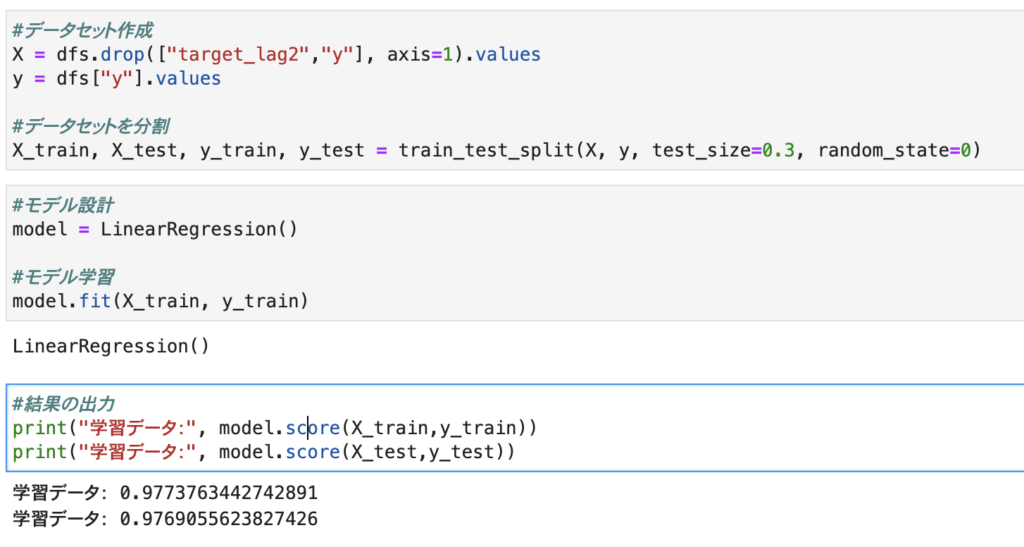
作成した特徴量を含めた全体のデータで重回帰分析を行います。
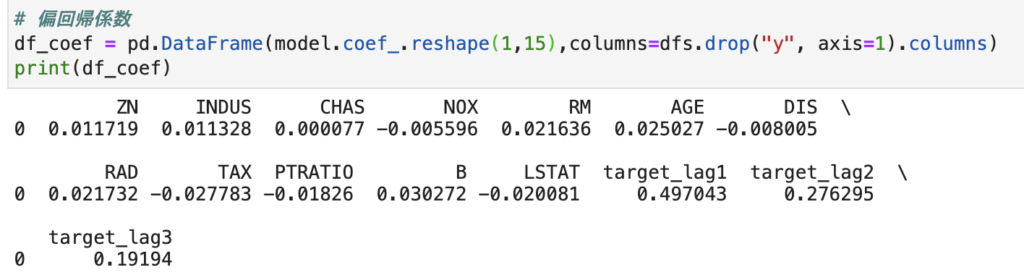
それぞれの変数の重みを確認します。
では、実際にマルチコ回避に向けて作業していきます。
まずは1.変数の削除から行ってみます。
まずは相関行列を見て、説明変数同士で相関の高いものを見つけます。
今回はtarget_lag1~3の変数の相関が非常に高いです。
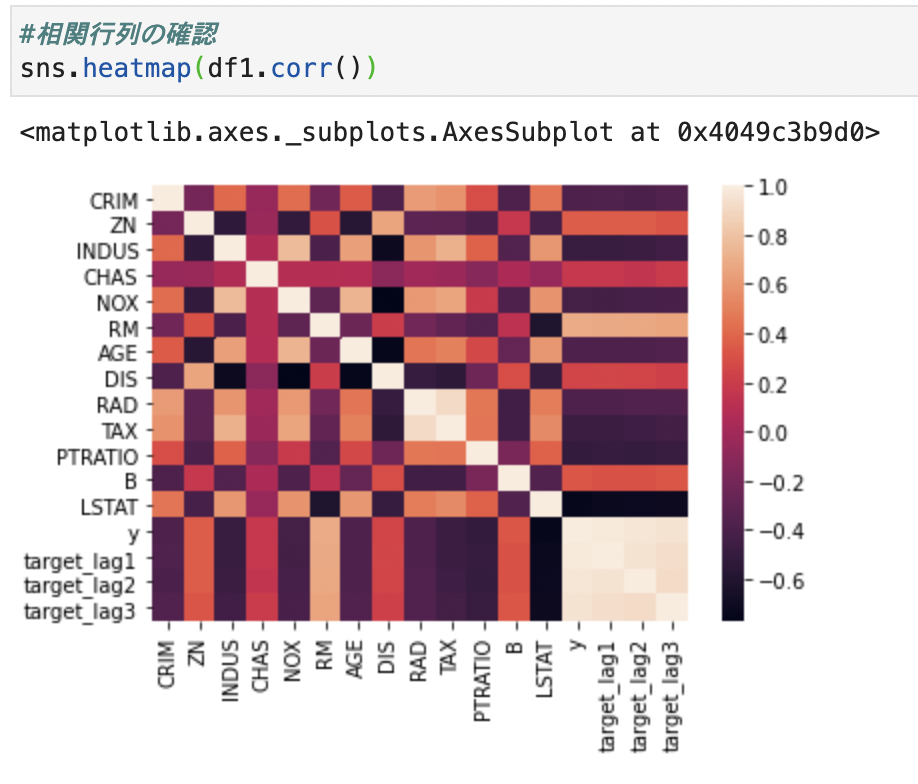
説明変数間の相関が高いtarget_lag2をまずは削除してみます。
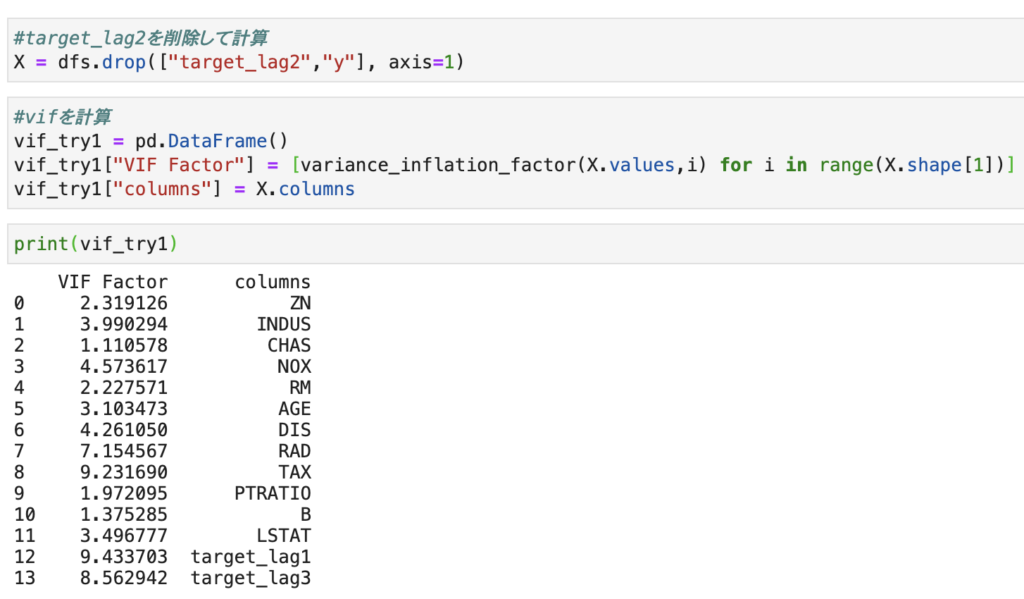
仮に10以上があった場合には再度相関行列を確認し変数を削除して値を確認します。
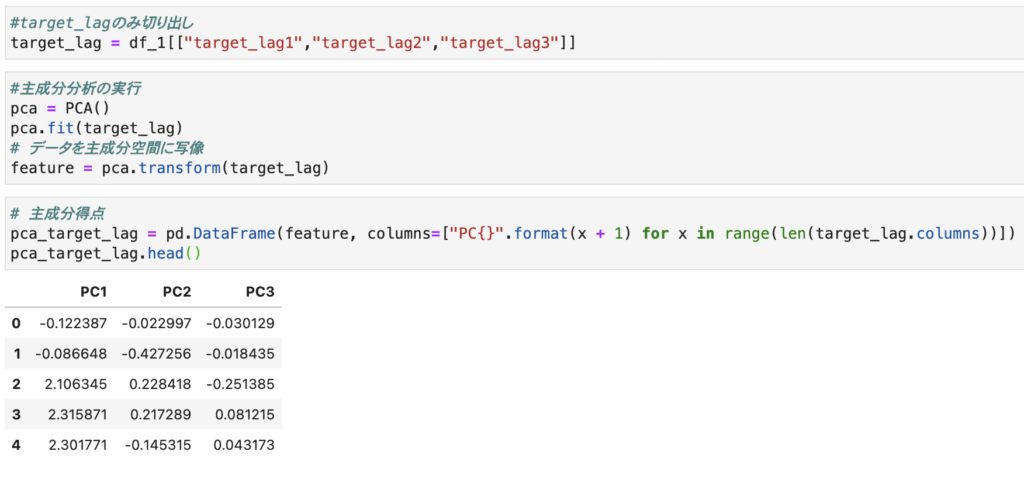
次に、主成分分析を行います。
今回はtarget_lagのみ主成分分析にかけ第一主成分だけ特徴量に持たせます。
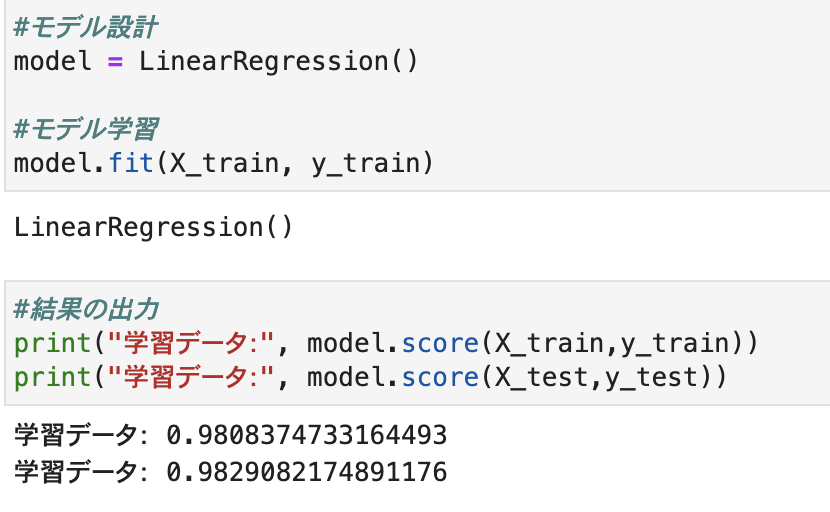
変数削除より精度が高いですが、何も処理せずにおこなった予測結果の方が精度が高いです。
○まとめ
主成分分析を行い重要な情報のみを変数として持たせる事によって変数を削除するよりも精度を保ちつつマルチコを解消することが出来ると考えられます。
マルチコが発生していることを知らずに特徴量の探索等を行うとミスリードされてしまう可能性が高いためモデルに学習させる前に一度、変数同士の相関係数を確認すると良いと思います。
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
コメントを残す