モデルのBlendingを実装してみた
今回は、モデルのBlending方法について記載させていただきます。
kaggleなどのコンペでスコアを上げる際の手法としても扱われているのがBlendingになります。
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
○Blendingとは?
Blendingとは、複数の異なるモデルの予測結果を組み合わせて最終的な予測を得る手法となります。
複数の異なるモデルを用いることで単一のモデルよりも優れた性能を得ることが目的となります。
○実装方法
1.モデルの選択
・ブレンディングを行う際は、異なる種類のモデルを選択することが重要です。例えば、線形回帰、ランダムフォレスト、勾配ブースティングなど様々なアルゴリズムやモデルを組み合わせることで互いのモデルの強みを活かしたモデルとなります。基本的にブレンディングに用いるモデルの精度は高くなくてもよく、2値分類等であれば0.5以上の正解率(ランダムより精度が高い)があれば良いとされています。
2.モデルの学習・予測結果の取得
・選択した複数のモデルの学習を行い予測結果を取得します。
3.Blending
・取得した予測結果を組み合わせます。Blendingの方法には下記の方法があります。
・平均、重み付け平均
・各モデルの予測値の中央値(分類問題時に使用)
・ロジスティック回帰や線形回帰などを利用し、モデルの予測を組み合わせる
4.評価
RMSE等、最適化したい評価指標の精度を確認します。
※Blendingは必ずモデルの精度向上につながるわけではないため、Blendingを試してみて精度が向上するかどうかを検証する必要があります。
○コードサンプル
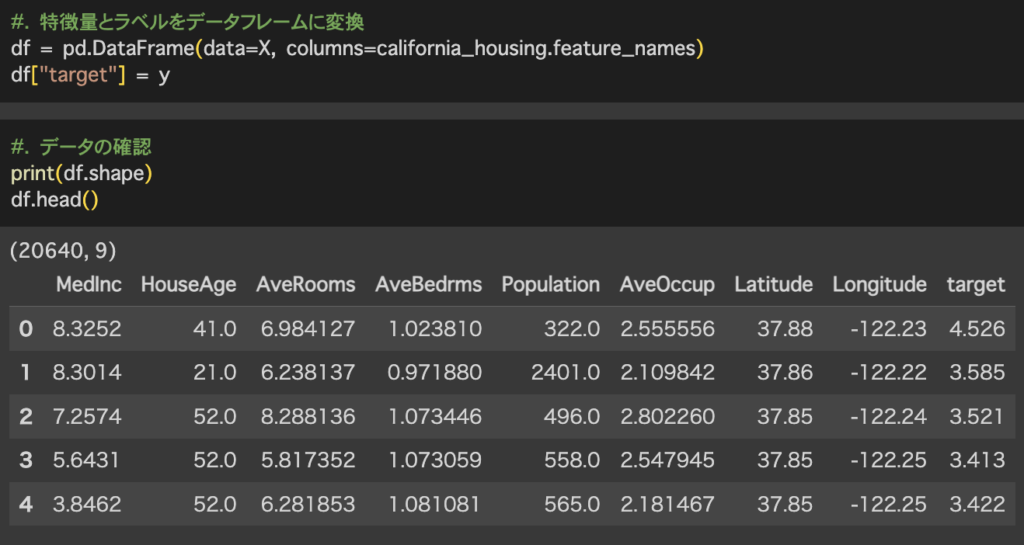
今回はサンプルデータとしてfetch_california_housingを用いて住宅価格を予測します。評価指標としては平均二乗誤差のMSEを用いることにします。
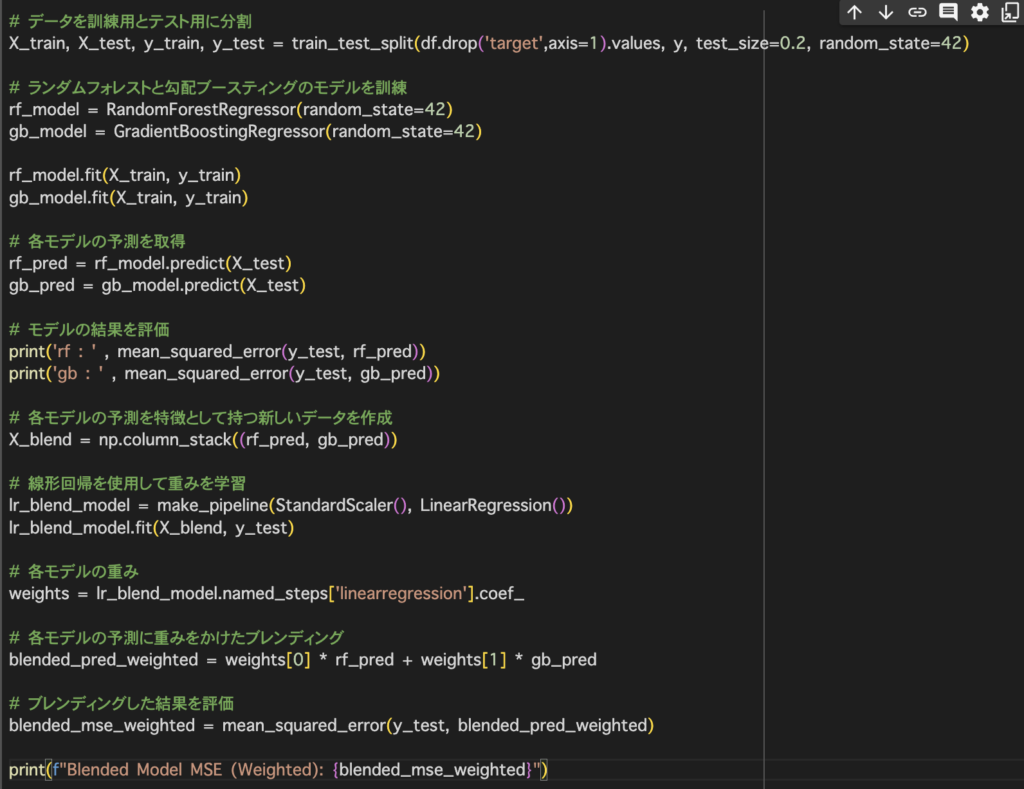

○Blendingで精度が下がるケース例
・ベースモデルの相関性が高く、同じような情報を学習している場合
・ベースモデルが過学習をしている場合
・適切な重みの設定ができていない場合
など様々なケースがあります。そのため、性能評価を行い有効か検証することが重要となります。
○最後に
このような形で分析した結果や試してみたことを週に1回(目標)ペースで掲載しています。データ分析のキャリアを歩み始めたのですが、データの解釈、分析力が低いと感じ今回、このような形でアウトプットをしていくことにしたため、ぜひ、アドバイスやご指摘をいただけると幸いです。
コメントを残す