マーケティングミックスモデリングについて今更ながら学んでみた
X(旧Twitter)を眺めていたら博報堂DYメディアパートナーズが作成したマーケティングミックスモデリングガイドブック(以下ガイドブック)を見つけました。昔から興味があった分野でしたのでこれを機にサンプルデータを用いた予算最適化まで実行してみました。
※このブログの内容は個人の意見・見解となります。また、記事の内容の正確性については保証いたしません。本ブログの目的は分析結果をアウトプットしていくことによる自身のデータ分析力向上を主としています。誤りや違うアプローチの方が良いという事も多分にあると思います。後学のため、「もっとこうしたらいい」や誤りを見つけた場合はコメント欄などでお知らせいただけると有難いです。
○MMMとは
ガイドブックからの引用となりますが、MMMとは「マーケティング施策がどれくらい/どのように事業貢献しているかを導く分析手法」となります。マーケティング施策と聞くとテレビCMやSNS広告から自社アプリまで幅広いメディア媒体がありますが、これらがどれだけ売上に繋がっているのか従来活用していたクッキー規制により把握が難しいという課題がありました。そこで、これらを活用したマーケティング施策による効果を導き予算配分を最適化し収益を向上させるために開発されたモデルになります。
○MMMのモデル構築プロセス
ガイドブックでは構築までのプロセスを「データの選択、データクレンジング、モデル構造の作成、パラメータの推定、モデルの検証、モデルの利用」の6つに分けて紹介されています。データの選択、データクレンジング、モデル構造の作成についてかいつまんで説明させていただきます。
・データの選択:
KPI(売上やアプリダウンロード数などの事業貢献を表す指標)、メディアへの広告(費用、インプレッション数など広告量を表す指標を用います。現在はインプレッション数が主流だそうです。)、製品・サービスに関するデータなどを用意します。一般的には日ごとまたは週ごとにまとめたデータを2年分以上用意するそうです。
・データクレンジング:
欠損値の補完、外れ値の確認、データ形式の変換、多重共線性の確認、正則化を行います。
特に多重共線性は正しく各メディア媒体ごとに寄与度を算出するには重要で、メディアAとメディアBのインプレッション数の間に強い相関がある場合、メディアAとメディアBは同じような動きをしていることになるためどちらのメディアがKPIに貢献したかを判断することができません。そのため、多重共線性が見られた場合は、該当項目を削除するか、統合するか、セグメント分けを行い多重共線性を緩和するかの手法を用います。
・モデル構造の作成
MMMのモデル構造は回帰モデルの数式に近いです。大きな違いとしてはHill関数とAdstockになります。今回はこのHill関数とAdstockについてどんなことをしているのかイメージをご説明させていただきます。

・Hill関数
広告による売上増加効果は回帰直線の用に広告費用を増やせば増やすだけ増加するのではなく、一定の値で頭打ちになるというのはなんとなくイメージができると思います。この頭打ちを表すための関数がHill関数になります。
・Adstock
広告を行なった際に、広告を行なった最初と比べ時間が経つにつれて広告の効果が薄まっていくというのは考えられるかなと思います。この広告の効果が減衰していく減衰効果を表すための変数変換がAdstockになります。
・パラメータの推定方法
推定方法には最小二乗法、正則化、ベイズ推定の3つがあり、解きたい問いによって異なる。KPIの予測精度を高めたい場合は正則化を、各メディアによる事業貢献度を推定したい場合はベイズ推定が有力とされている。
○実際にMMMを実行してみます
今回はpythonでMMMを実装できるlightweight_mmmを利用してgithub上にあるsimple_end_to_end_demo.ipynbを元に行います。今回利用するライブラリは下記になります。
1.データの準備
サンプルデータとして学習に利用する104週分のデータ+testに利用する13週分のデータを用いて行います。メディアの数は3つ、その他の特徴量として1つ用意します。

shapeは(データサイズ(今回の場合は104+13で117), メディア数(今回は3))
・extra_features:分析に追加したいその他の特徴量(休日やイベントの情報など必要に応じて追加)
shapeは(データサイズ, その他の特徴量(今回は1))
・target:推定したいKPI(売上、アプリダウンロード数) shapeは(データサイズ,)
・costs:メディアにかかるトータルコスト shapeは(1, メディア数)
次に13週分のデータをtestとして使用したいため最後の13週間だけ残して学習データを作成します。

2.データの正規化
lightweight_mmmには正規化を行うためのCustomScalerというClassが用意されているためimportすることで実行可能です。
CustomeScalerでは乗算と除算の2つを使用することができます。データセットを100倍してスケール七場合はmultiply_by=100と引数に入力することで実行できます。平均値を掛けたい場合はmultiply_by=jnp.meanで実行できます。

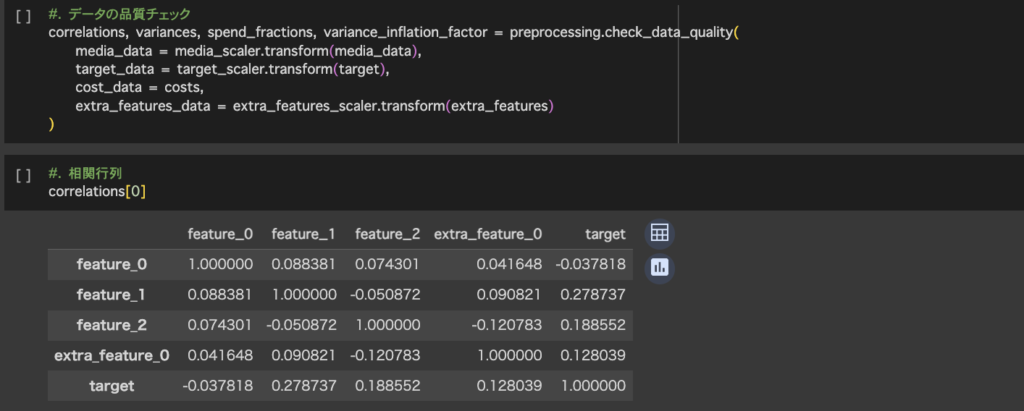
3.データのチェック
実際にMMMを実行する際には各メディアの相関係数や支出割合など確認する必要があります。今回は相関係数を確認します。
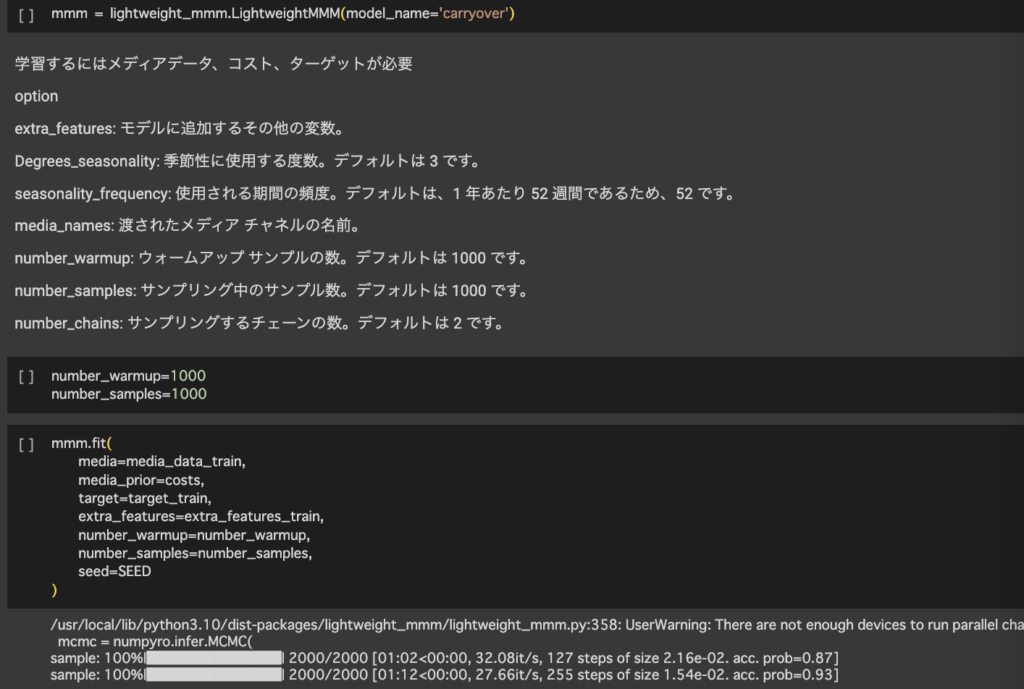
4.モデルの学習
チェックまで完了したらモデルに学習させていきます。使用するのはlightweight_mmm.LightweightMMMを使用します。今回はcarryoverをmodel_nameに渡していますが他にもadstock、hill_adstockもあり3つの中から選択する形となります。それぞれの特徴は下記になります。
・carryover:広告の影響が何日かにわたって持続するという仮定
・adstock:広告の影響は最初に効果的であり、時間が経つにつれて影響力が減少するという仮定
・hill_adstock:広告が最初は急速に消費者に影響を与え、一定の水準で飽和するという仮定
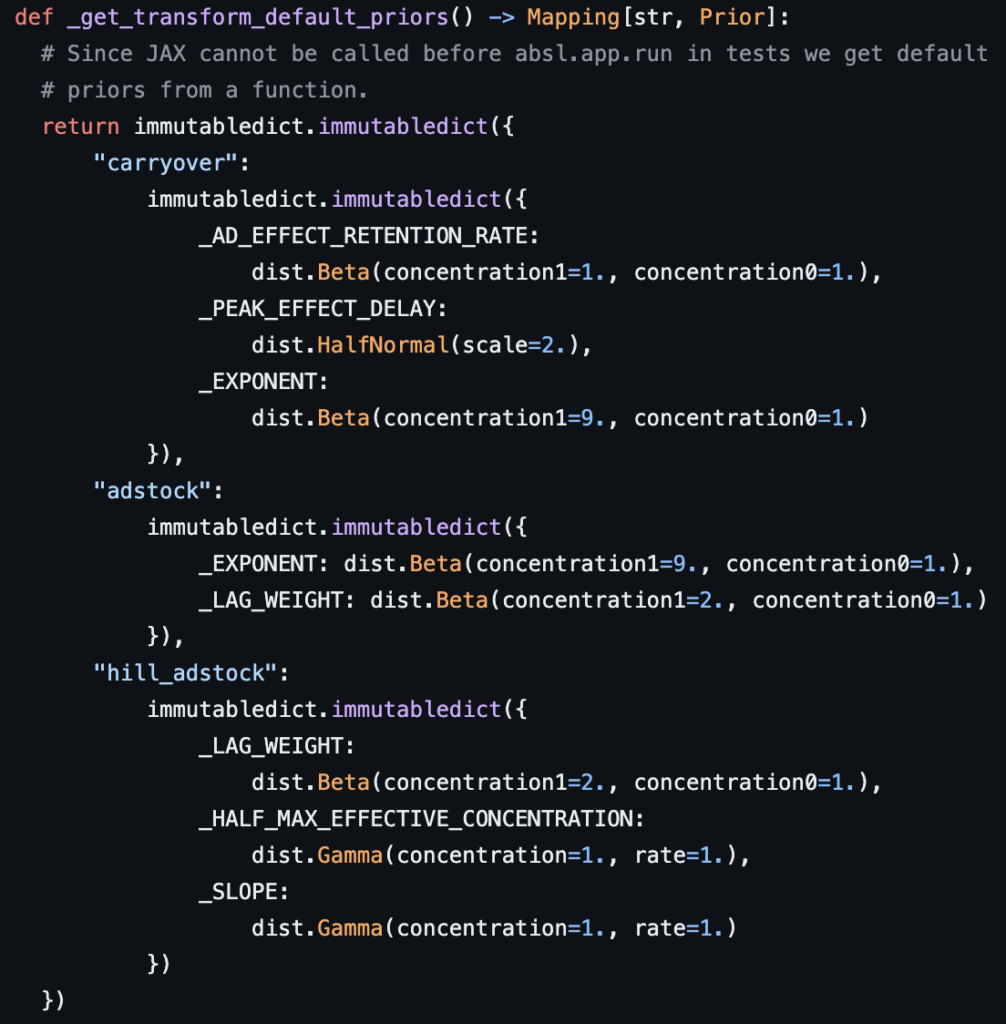
carryover、adstock、hill_adstockの事前分布は下記のコードで決められています。
・carryover:広告の影響がどれだけ持続するかをBeta分布、ピークの効果がどれだけ残るかをHalfNormal分布、広告の持続影響が時間の経過とともにどれだけ減少するかをBeta分布で表しています。
・adstock:広告の持続影響が最初にどの程度大きいかを示すのにBeta分布、広告の持続影響が時間の経過とともにどれだけ減少するかをBeta分布で表している。
・hill_adstock:広告の初期の効果をBeta分布、ピーク時の効果をGamma分布、広告の影響が時間の経過とともにどれだけ急速に減少するかをGamma分布で表しています。
・結果の確認
fitでMCMCを実行し、パラメータの統計量を確認します。
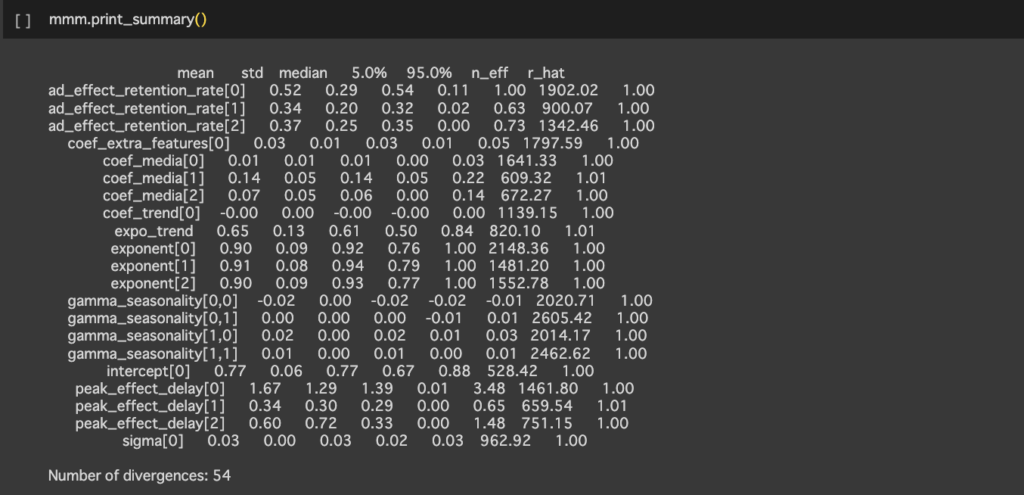
分布もplotすることができます。
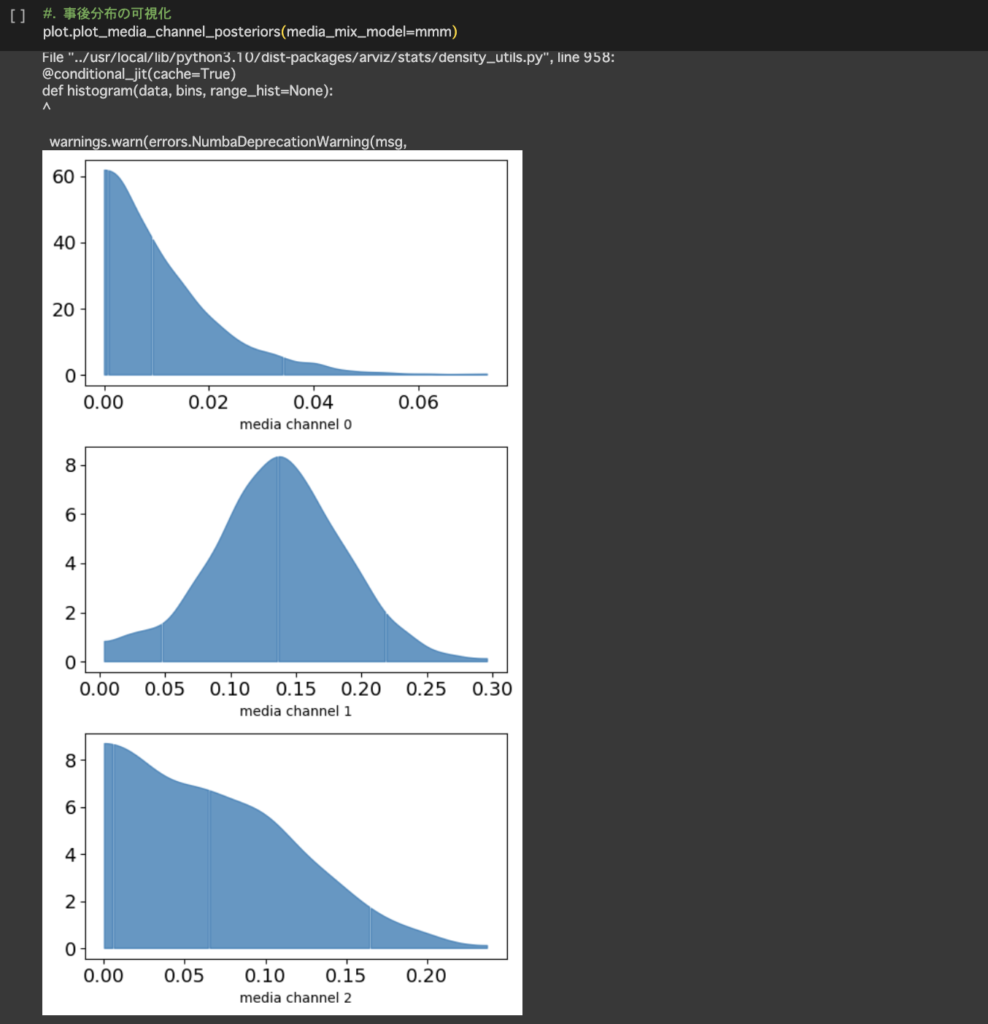
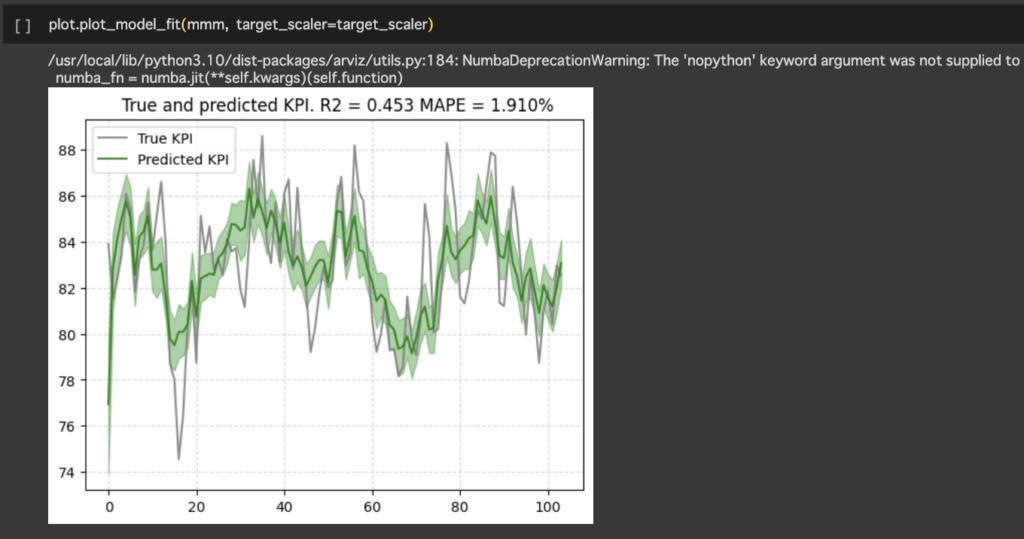
・予測結果の確認
予測結果の当てはまりの良さを確認もできます。
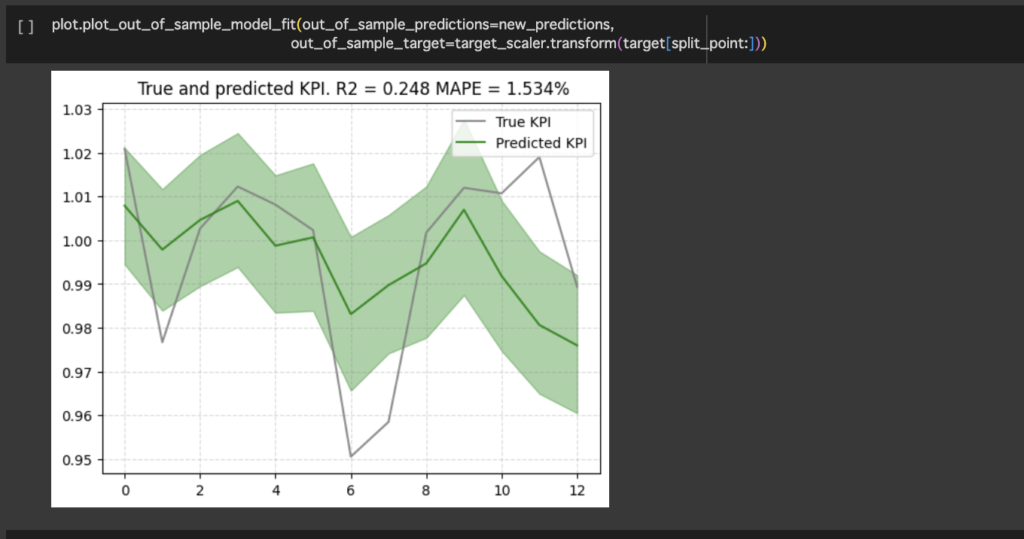
testデータを用いてtargetの推定も可能です。
・予算配分の最適化
各メディアの予算配分を最適化することも可能です。
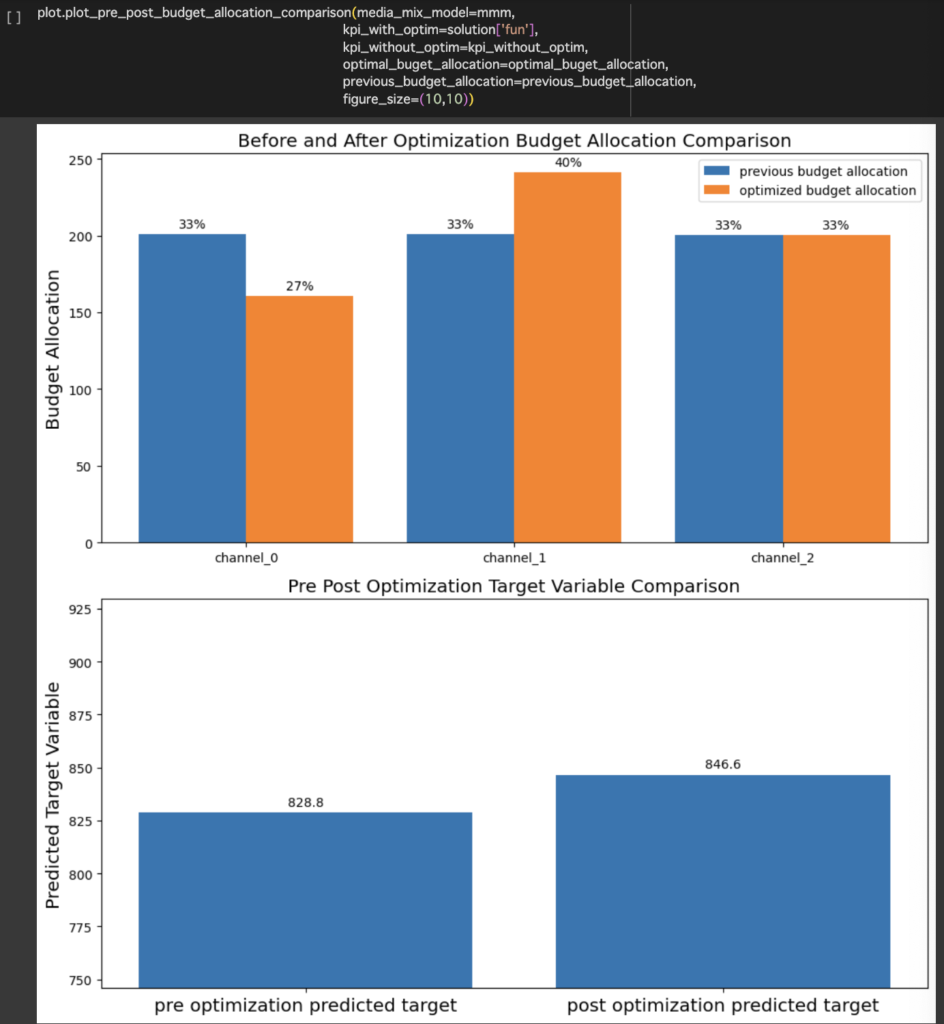
※デフォルトではトレーニングに使用される最大及び最小の値の20%に留まるように最適化されるため注意が必要です。
○まとめ
今回はMMMについて学習し実際にサンプルデータを用いて実装してみました。MMMを実行するためのコード自体はパッケージを用いることで簡単に実行できそうですが、何をKPIとして設定するか、データは必要な分だけ用意できるか、データのクレンジング、モデル構造には何を選択するかなど実際にモデルを構築し実行するまでに超えなければいけないハードルが沢山あることがわかりました。実際に実務で活用できるよう引き続き学習したいと思います。
○引用、参考
・博報堂DYメディアパートナーズ マーケティングミックスモデリングガイドブック:https://docs.google.com/presentation/d/1EubeiD6dAhws1WMcp7tBRYsf3Jvs6cORHDllpKqFtzg/edit?_fsi=g0W33b0Y#slide=id.p1
・lightweight_mmm github:https://github.com/google/lightweight_mmm/tree/main
・lightweight_mmm ドキュメント:https://lightweight-mmm.readthedocs.io/en/latest/api.html
・論文 Jin, Y., Wang, Y., Sun, Y., Chan, D., & Koehler, J. (2017). Bayesian Methods for Media Mix Modeling with Carryover and Shape Effects. Google Inc.:https://storage.googleapis.com/pub-tools-public-publication-data/pdf/b20467a5c27b86c08cceed56fc72ceadb875184a.pdf
コメントを残す